דיאגונליזציה קוונטית של קרילוב
בשיעור זה על דיאגונליזציה קוונטית של קרילוב (KQD) נענה על השאלות הבאות:
- מהי שיטת קרילוב באופן כללי?
- מדוע שיטת קרילוב עובדת ובאילו תנאים?
- כיצד מחשוב קוונטי ממלא תפקיד בכך?
החלק הקוונטי של החישובים מבוסס במידה רבה על העבודה במקור [1].
הסרטון שלהלן נותן סקירה כללית של שיטות קרילוב במחשוב קלאסי, מניע את השימוש בהן, ומסביר כיצד מחשוב קוונטי יכול למלא תפקיד בזרם העבודה הזה. הטקסט שלאחר מכן מציע פירוט נוסף ומממש שיטת קרילוב הן בצורה קלאסית והן באמצעות מחשב קוונטי.
1. מבוא לשיטות קרילוב
שיטת מרחב קרילוב יכולה להתייחס לכל אחת ממספר שיטות הבנויות סביב מה שנקרא מרחב קרילוב. סקירה מלאה שלהן חורגת מהיקף שיעור זה, אך מקורות [2-4] יכולים לספק רקע מהותי יותר. כאן נתמקד במה שמרחב קרילוב הוא, כיצד ומדוע הוא שימושי בפתרון בעיות ערכים עצמיים, ולבסוף כיצד ניתן ליישמו על מחשב קוונטי.
הגדרה: נתונה מטריצה סימטרית, חיובית למחצה בשם , מרחב קרילוב מסדר הוא המרחב הנפרש על ידי וקטורים המתקבלים על ידי כפל בחזקות גבוהות יותר של מטריצה , עד , עם וקטור ייחוס .
למרות שהוקטורים לעיל פורשים את מה שאנו קוראים מרחב קרילוב, אין סיבה לחשוב שהם יהיו ניצבים זה לזה. לעיתים קרובות משתמשים בתהליך אורתונורמליזציה איטרטיבי הדומה לאורתוגונליזציה של גראם-שמידט. כאן התהליך שונה במקצת שכן כל וקטור חדש מאורתוגונל לשאר בעת יצירתו. בהקשר זה זה נקרא איטרציית ארנולדי. החל מהוקטור הראשוני , יוצרים את הוקטור הבא , ולאחר מכן מוודאים שהוקטור השני ניצב לראשון על ידי חיסור ההיטל שלו על . כלומר
כעת קל לראות ש- שכן
אנחנו עושים אותו הדבר עבור הוקטור הבא, ומוודאים שהוא ניצב לשני הקודמים:
אם נחזור על תהליך זה עבור כל הוקטורים, יהיה לנו בסיס אורתונורמלי מלא למרחב קרילוב. שימו לב שתהליך האורתוגונליזציה כאן יניב אפס ברגע ש-, מכיוון ש- וקטורים ניצבים בהכרח פורשים את המרחב המלא. התהליך יניב גם אפס אם וקטור כלשהו הוא וקטור עצמי של שכן כל הוקטורים הבאים יהיו כפולות של אותו וקטור.
1.1 דוגמה פשוטה: קרילוב ביד
נעבור שלב אחר שלב על יצירת מרחב קרילוב על מטריצה קטנה באופן טריוויאלי, כדי שנוכל לראות את התהליך. אנחנו מתחילים עם מטריצה ראשונית המעניינת אותנו:
לדוגמה קטנה זו, אנחנו יכולים לקבוע את הוקטורים העצמיים וערכי העצמי בקלות אפילו ביד. אנחנו מציגים כאן את הפתרון המספרי.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy sympy
# One might use linalg.eigh here, but later matrices may not be Hermitian. So we use
# linalg.eig in this lesson.
import numpy as np
A = np.array([[4, -1, 0], [-1, 4, -1], [0, -1, 4]])
eigenvalues, eigenvectors = np.linalg.eig(A)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
The eigenvalues are [2.58578644 4. 5.41421356]
The eigenvectors are [[ 5.00000000e-01 -7.07106781e-01 5.00000000e-01]
[ 7.07106781e-01 1.37464400e-16 -7.07106781e-01]
[ 5.00000000e-01 7.07106781e-01 5.00000000e-01]]
אנחנו רושמים אותם כאן להשוואה מאוחרת יותר:
אנחנו רוצים לחקור כיצד תהליך זה עובד (או נכשל) כאשר אנחנו מגדילים את ממד מרחב קרילוב שלנו, . לצורך זה, נישם את התהליך הבא:
- נייצר תת-מרחב של מרחב הוקטורים המלא החל מוקטור שנבחר באקראי (נקרא לו אם הוא כבר מנורמל, כמפורט לעיל).
- נטיל את המטריצה המלאה על אותו תת-מרחב, ונמצא את ערכי העצמי של אותה מטריצה מוטלת .
- נגדיל את גודל תת-המרחב על ידי יצירת וקטורים נוספים, ונוודא שהם אורתונורמליים, באמצעות תהליך הדומה לאורתוגונליזציה של גראם-שמידט.
- נטיל את על תת-המרחב הגדול יותר ונמצא את ערכי העצמי של המטריצה המתקבלת, .
- נחזור על כך עד שערכי העצמי מתכנסים (או במקרה צעצוע זה, עד שיצרנו וקטורים הפורשים את מרחב הוקטורים המלא של המטריצה המקורית ).
מימוש רגיל של שיטת קרילוב לא יצטרך לפתור את בעיית ערכי העצמי עבור המטריצה המוטלת על כל מרחב קרילוב תוך כדי בנייתו. ניתן לבנות את תת-המרחב של הממד הרצוי, להטיל את המטריצה על תת-המרחב הזה, ולדיאגונל את המטריצה המוטלת. הטלה ודיאגונליזציה בכל ממד תת-מרחב מתבצעות רק לצורך בדיקת ההתכנסות.
ממד :
אנחנו בוחרים וקטור אקראי, נניח
אם הוא עדיין לא מנורמל, מנרמלים אותו.
כעת אנחנו מטילים את המטריצה שלנו על תת-המרחב של וקטור זה בלבד:
זוהי ההטלה של המטריצה על מרחב קרילוב שלנו כאשר הוא מכיל וקטור בודד, . ערך העצמי של מטריצה זו הוא 4 באופן טריוויאלי. אנחנו יכולים לחשוב על זה כאומדן מסדר אפס של ערכי העצמי (במקרה זה רק אחד) של . למרות שזהו אומדן גרוע, הוא בסדר גודל הנכון.
ממד :
כעת אנחנו יוצרים את הוקטור הבא בתת-המרחב שלנו על ידי פעולה עם על הוקטור הקודם:
כעת אנחנו מחסירים את ההיטל של וקטור זה על הוקטור הקודם שלנו כדי להבטיח ניצבות.
אם הוא עדיין לא מנורמל, מנרמלים אותו. במקרה זה, הוקטור כבר היה מנורמל, ולכן
כעת אנחנו מטילים את המטריצה A שלנו על תת-המרחב של שני הוקטורים האלה:
אנחנו עדיין נותרים עם הבעיה של מציאת ערכי העצמי של מטריצה זו. אבל מטריצה זו קטנה מעט מהמטריצה המלאה. בבעיות הכוללות מטריצות גדולות מאוד, עבודה עם תת-המרחב הקטן יותר הזה עשויה להיות מועילה מאוד.
למרות שזה עדיין לא אומדן טוב, הוא טוב יותר מהאומדן מסדר אפס. נבצע זאת עוד איטרציה אחת, כדי לוודא שהתהליך ברור. עם זאת, זה מפחית את הנקודה של השיטה, שכן בסופו של דבר נדיאגונל מטריצה 3×3 באיטרציה הבאה, כלומר לא חסכנו זמן או כוח חישובי.
ממד :
כעת אנחנו יוצרים את הוקטור הבא בתת-המרחב שלנו על ידי פעולה עם A על הוקטור הקודם:
כעת אנחנו מחסירים את ההיטל של וקטור זה על שני הוקטורים הקודמים שלנו כדי להבטיח ניצבות.
אם הוא עדיין לא מנורמל, מנרמלים אותו. במקרה זה, הוקטור כבר היה מנורמל, ולכן
כעת אנחנו מטילים את המטריצה שלנו על תת-המרחב של הוקטורים האלה:
כעת אנחנו מוצאים את ערכי העצמי:
ערכי עצמי אלה הם בדיוק ערכי העצמי של המטריצה המקורית . זה חייב להיות המקרה, שכן הרחבנו את מרחב קרילוב שלנו לפרוש את מרחב הוקטורים המלא של המטריצה המקורית .
בדוגמה זו, שיטת קרילוב עשויה שלא להיראות קלה במיוחד מאשר דיאגונליזציה ישירה. אכן, כפי שנראה בסעיפים מאוחרים יותר, שיטת קרילוב מועילה רק מעל ממד מטריצה מסוים; זה נועד לסייע לנו לפתור בעיות ערכים עצמיים/וקטורים עצמיים של מטריצות גדולות מאוד.
זוהי הדוגמה היחידה שנציג כשנעשתה "ביד", אך סעיף 2 להלן מציג דוגמאות חישוביות.
הבהרת מונחים
אי-הבנה נפוצה היא שיש רק מרחב קרילוב יחיד לבעיה נתונה. אבל כמובן, מכיוון שיש וקטורים ראשוניים רבים שניתן להחיל עליהם את המטריצה, ישנם מרחבי קרילוב אפשריים רבים. נשתמש בביטוי "מרחב קרילוב" (בה״א הידיעה) רק כדי להתייחס למרחב קרילוב ספציפי שכבר הוגדר לדוגמה ספציפית. לגישות פתרון בעיות כלליות נתייחס ל"מרחב קרילוב" (ללא ה״א הידיעה). הבהרה אחרונה היא שתקפי להתייחס ל"מרחב קרילוב". לעיתים קרובות רואים אותו מכונה "תת-מרחב קרילוב" בגלל השימוש בו בהקשר של הטלת מטריצות ממרחב ראשוני לתת-מרחב. בהתאם להקשר זה, נתייחס אליו בעיקר כתת-מרחב כאן.
בדוק את הבנתך
הסבר מדוע אינו (א) שימושי, ו-(ב) אפשרי להרחיב את הממד של מרחב קרילוב מעבר לממד של המטריצה המעניינת.
Answer
(א) מאחר שאנו מאורתונורמלים את הוקטורים בעת יצירתם, קבוצה של וקטורים כאלה תיצור בסיס מלא, כלומר ניתן להשתמש בצירוף ליניארי שלהם ליצירת כל וקטור במרחב.
(ב) תהליך האורתוגונליזציה מורכב מחיסור ההיטל של וקטור חדש על כל הוקטורים הקודמים. אם כל הוקטורים הקודמים פורשים את מרחב הוקטורים המלא, אז חיסור ההיטלים על תת-המרחב המלא תמיד ישאיר אותנו עם וקטור אפס.
נניח שחוקר עמית מדגים את שיטת קרילוב המיושמת על מטריצת צעצוע קטנה. האם יש משהו שגוי בבחירת המטריצה והוקטור הראשוני ?
ו-
Answer
עמיתך בחר בטעות וקטור עצמי כוקטור הראשוני שלו/שלה. פעולה עם המטריצה על הוקטור הראשוני פשוט תחזיר את אותו וקטור בחזרה, כשהוא מוכפל בערך העצמי. זה לא ייצור תת-מרחב בעל ממד גדל. יעץ לעמיתך לבחור וקטור ראשוני אחר, ולוודא שאינו וקטור עצמי.
יישם את שיטת קרילוב על המטריצה הנתונה, תוך בחירת וקטור ראשוני חדש מתאים. רשום את האומדנים של ערך העצמי המינימלי בסדר 0 ובסדר 1 של מרחב קרילוב שלך.
Answer
ישנן תשובות אפשריות רבות בהתאם לבחירת הוקטור הראשוני. נבחר:
כדי לקבל את אנחנו מיישמים את פעם אחת על , ולאחר מכן עושים את ניצב ל-
בסדר 0, ההטלה על מרחב קרילוב שלנו היא
בסדר 1, ההטלה על מרחב קרילוב זה היא
ניתן לעשות זאת ביד, אך קל ביותר לעשות זאת באמצעות numpy:
import numpy as np
vstar = np.array([[1/np.sqrt(3),1/np.sqrt(3),1/np.sqrt(3)],[-1/np.sqrt(6),np.sqrt(2/3),-1/np.sqrt(6)]]
)
A = np.array([[1, 1, 0],
[1, 1, 1],
[0, 1, 1]])
v = np.array([[1/np.sqrt(3),-1/np.sqrt(6)],[1/np.sqrt(3),np.sqrt(2/3)],[1/np.sqrt(3),-1/np.sqrt(6)]])
proj = vstar@A@v
print(proj)
eigenvalues, eigenvectors = np.linalg.eig(proj)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
פלט:
[[ 2.33333333 0.47140452]
[ 0.47140452 -0.33333333]]
The eigenvalues are [ 2.41421356 -0.41421356]
The eigenvectors are [[ 0.98559856 -0.16910198]
[ 0.16910198 0.98559856]]
אומדן ערך העצמי המינימלי הוא -0.414.
1.2 סוגי שיטות קרילוב
"שיטות מרחב קרילוב" יכולות להתייחס לכל אחת ממספר טכניקות איטרטיביות המשמשות לפתרון מערכות ליניאריות גדולות ובעיות ערכים עצמיים. מה שמשותף לכולן הוא שהן בונות פתרון משוער ממרחב קרילוב
כאשר הוא הניחוש הראשוני (ראה מקור [5]). הן נבדלות בבחירת האופן שבו הן בוחרות את הקירוב הטוב ביותר מתוך תת-מרחב זה, תוך איזון גורמים כגון קצב התכנסות, שימוש בזיכרון ועלות חישובית כוללת. המיקוד של שיעור זה הוא לנצל את המחשוב הקוונטי בהקשר של שיטות מרחב קרילוב; דיון ממצה בשיטות אלה חורג מהיקפו. ההגדרות הקצרות שלהלן הן לשם הקשר בלבד וכוללות כמה מקורות לחקירת שיטות אלה עוד יותר.
שיטת הגרדיאנט הצמוד (CG): שיטה זו משמשת לפתרון מערכות ליניאריות סימטריות, חיוביות מוגדרות [6]. היא ממזערת את ה-A-נורמה של השגיאה בכל איטרציה, מה שהופך אותה ליעילה במיוחד עבור מערכות הנובעות מ-PDEs אליפטיים מדיסקרטיזציה [7]. נשתמש בגישה זו בסעיף הבא כדי להניע מדוע מרחב קרילוב יהיה תת-מרחב יעיל שבו לחפש פתרונות משופרים למערכות ליניאריות.
שיטת השארית המינימלית המוכללת (GMRES): זו מיועדת לפתרון מערכות ליניאריות לא-סימטריות כלליות. היא ממזערת את נורמת השארית על פני מרחב קרילוב בכל איטרציה, מה שהופך אותה לאמינה אך פוטנציאלית עתירת זיכרון עבור מערכות גדולות [7].
שיטת השארית המינימלית (MINRES): שיטה זו משמשת לפתרון מערכות ליניאריות סימטריות לא-מוגדרות. היא דומה ל-GMRES אך מנצלת את הסימטריה של המטריצה להפחתת עלות חישובית [8].
גישות נוספות שראוי לציין כוללות את שיטת האורתוגונליזציה המלאה (FOM), הקשורה קשר הדוק לשיטת ארנולדי לבעיות ערכים עצמיים, שיטת הגרדיאנט הצמוד הדו-כיווני (BiCG), ושיטת הצמצום בממד המושרה (IDR).
1.3 מדוע שיטת מרחב קרילוב עובדת
כאן ננסה להניח שיטת מרחב קרילוב צריכה להיות דרך יעילה לקרוב ערכים עצמיים של מטריצות באמצעות מיצוב איטרטיבי של קירובי וקטורים עצמיים, דרך עדשת הירידה התלולה ביותר. נטען שבהינתן ניחוש ראשוני של מצב הבסיס, המרחב של התיקונים העוקבים לניחוש הראשוני הזה המניב את ההתכנסות המהירה ביותר הוא מרחב קרילוב. אנחנו נמנע מהוכחה קפדנית של התנהגות ההתכנסות.
נניח שהמטריצה המעניינת שלנו היא סימטרית וחיובית מוגדרת. זה הופך את הטיעון שלנו לרלוונטי ביותר לשיטת CG לעיל. אנחנו לא מניחים כלום לגבי דלילות כאן; ולא אנחנו טוענים ש- חייבת להיות הרמיטית (מה שהיא חייבת להיות אם היא המילטוניאן).
בדרך כלל אנחנו רוצים לפתור בעיה מהצורה
אפשר לדמיין ש- כאשר הוא קבוע כלשהו, כמו בבעיית ערכים עצמיים. אבל ניסוח הבעיה שלנו נשאר כללי יותר לעת עתה.
אנחנו מתחילים עם וקטור שהוא פתרון משוער. למרות שיש קווי דמיון בין ניחוש זה ל- בסעיף 1.1, אנחנו לא מנצלים אותם כאן. לניחוש שלנו יש שגיאה, שאנו קוראים לה
אנחנו גם מגדירים את השארית
כאן אנחנו משתמשים ב- גדולה כדי להבחין בין השארית לממד מרחב קרילוב שלנו .

כעת אנחנו רוצים לבצע שלב תיקון מהצורה
שאנו מקווים שישפר את הקירוב שלנו. כאן הוא וקטור כלשהו שעדיין יש לקבוע. יהי השגיאה לאחר ביצוע התיקון. אז

אנחנו מעוניינים כיצד מתנהגת השגיאה שלנו כאשר היא עוברת טרנספורמציה על ידי המטריצה שלנו. אז בואו נחשב את ה--נורמה של השגיאה. כלומר
כאשר השתמשנו בסימטריה של וגם ב- כאן הוא קבוע עצמאי מ-. כאמור בסעיף 1.2, ה--נורמה של השגיאה אינה הכמות היחידה שנוכל לבחור למזער, אבל היא טובה. אנחנו רוצים לראות כיצד כמות זו משתנה עם בחירת וקטורי התיקון אז אנחנו מגדירים את הפונקציה על ידי הגדרה
היא פשוט השגיאה כפונקציה של התיקון הנמדדת ב--נורמה. לכן, אנחנו רוצים לבחור כך ש- יהיה קטן ככל האפשר. לצורך זה, אנחנו מחשבים את הגרדיאנט של . תוך שימוש בסימטריה של יש לנו
הגרדיאנט מצביע בכיוון העלייה התלולה ביותר, כלומר הנגדי שלו נותן לנו את הכיוון שבו הפונקציה יורדת הכי הרבה: כיוון הירידה התלולה ביותר. בניחוש הראשוני שלנו , שם , יש לנו ש- לפיכך, הפונקציה יורדת הכי הרבה בכיוון השארית לכן הבחירה הראשונית שלנו תתרווח ביותר בתוספת הוקטור עבור סקלר כלשהו.
בשלב הבא, אנחנו בוחרים שוב וקטור ומוסיפים את ערכו לקירוב הנוכחי. תוך שימוש באותו טיעון כקודם אנחנו בוחרים עבור סקלר כלשהו. אנחנו ממשיכים בדרך זו, כך שהאיטרציה ה- של הוקטור שלנו היא
באופן שקול, אנחנו רוצים לבנות את המרחב ממנו אנחנו בוחרים את האומדנים המשופרים שלנו על ידי הוספת , , וכן הלאה, בסדר. הוקטור המוערך ה- נמצא ב-
כעת, תוך שימוש ביחס ש-
אנחנו רואים ש-
כלומר, המרחב שאנו בונים שמקרב בצורה היעילה ביותר את הפתרון הנכון הוא בדיוק המרחב הנבנה על ידי פעולה עוקבת של המטריצה על מרחב קרילוב הוא המרחב הנפרש על ידי הוקטורים של כיווני הירידה התלולה ביותר העוקבים.
לבסוף, אנחנו חוזרים ומציינים שלא ביצענו טענות מספריות על הסקלה של גישה זו, ואף לא דנו ביתרון ההשוואתי למטריצות דלילות. זה נועד רק להניע את השימוש בשיטות מרחב קרילוב, ולהוסיף תחושה אינטואיטיבית כלשהי לגביהן. כעת נחקור את ההתנהגות של שיטות אלה מספרית.
בדוק את הבנתך
בזרימת העבודה לעיל, הצענו למזער את ה--נורמה של השגיאה. אילו כמויות אחרות ניתן לשקול למזערן בחיפוש אחר מצב הבסיס וערך העצמי שלו?
Answer
ניתן לדמיין שימוש בוקטור השארית במקום ה--נורמה של השגיאה. ייתכנו מקרים שבהם שיקול וקטור השגיאה עצמו יהיה שימושי.
2. שיטות Krylov בחישוב קלאסי
בחלק זה נממש איטרציות Arnoldi חישובית, כדי לנצל תת-מרחב Krylov לפתרון בעיות ערכים עצמיים. נתחיל ביישום על דוגמה קטנה, ואז נבדוק כיצד זמן החישוב משתנה עם גדלו של המטריצה. רעיון מרכזי כאן הוא שיצירת הווקטורים הפורשים את מרחב Krylov היא התורמת הגדולה ביותר לזמן החישוב הכולל הנדרש. הזיכרון הנדרש משתנה בין שיטות Krylov שונות, אך מגבלות זיכרון עשויות להגביל את השימוש בשיטות Krylov המסורתיות.
2.1 דוגמה פשוטה בקנה מידה קטן
בתהליך יצירת תת-מרחב Krylov, נצטרך לאורתונורמל את הווקטורים שבתת-המרחב שלנו. נגדיר פונקציה שמקבלת ווקטור קיים מתת-המרחב שלנו vknown (לא בהכרח מנורמל) וווקטור מועמד להוספה לתת-המרחב vnext, ומבצעת אורתוגונליזציה של vnext ביחס ל-vknown ומנרמלת אותו. נגדיר גם פונקציה שעוברת על כל הווקטורים הקיימים בתת-מרחב Krylov שלנו, כדי להבטיח קבוצה אורתונורמלית מלאה.
# vknown is some established vector in our subspace. vnext is one we wish to add,
# which must be orthogonal to vknown.
def orthog_pair(vknown, vnext):
vknown = vknown / np.sqrt(vknown.T @ vknown)
diffvec = vknown.T @ vnext * vknown
vnext = vnext - diffvec
return vnext
# v is the candidate vector to be added to our subspace. s is the existing subspace.
def orthoset(v, s):
v = v / np.sqrt(v.T @ v)
temp = v
for i in range(len(s)):
temp = orthog_pair(s[i], temp)
v = temp / np.sqrt(temp.T @ temp)
return v
עכשיו נגדיר פונקציה שבונה תת-מרחב Krylov שגדל בהדרגה, עד שמרחב וקטורי Krylov פורש את המרחב המלא של המטריצה המקורית. זה יאפשר לנו לראות כמה הערכים העצמיים שהתקבלו בשיטת תת-מרחב Krylov תואמים לערכים המדויקים, כפונקציה של ממד תת-מרחב Krylov. חשוב לציין שהפונקציה krylov_full_build מחזירה את וקטורי Krylov, את ההמילטוניאנים המוקרנים, את הערכים העצמיים, ואת הזמן הנדרש.
# Necessary imports and definitions to track time in microseconds
import time
def time_mus():
return int(time.time() * 1000000)
# This function constructs a Krylov subspace that spans the whole space of the original matrix.
# Input:
# v0 : initial vector
# matrix : original matrix to be diagonalized
# Output:
# ks : Krylov vectors
# Hs : projected Hamiltonians
# eigs : eigenvalues
# k_tot_times : time required for the operation
def krylov_full_build(v0, matrix):
t0 = time_mus()
b = v0 / np.sqrt(v0 @ v0.T)
A = matrix
ks = []
ks.append(b)
Hs = []
eigs = []
Hs.append(b.T @ A @ b)
eigs.append(np.array([b.T @ A @ b]))
k_tot_times = []
for j in range(len(A) - 1):
vec = A @ ks[j].T
ortho = orthoset(vec, ks)
ks.append(ortho)
ksarray = np.array(ks)
Hs.append(ksarray @ A @ ksarray.T)
eigs.append(np.linalg.eig(Hs[j + 1]).eigenvalues)
k_tot_times.append(time_mus() - t0)
# Return the Krylov vectors, the projected Hamiltonians, the eigenvalues,
# and the total time required.
return (ks, Hs, eigs, k_tot_times)
נבחן זאת על מטריצה שעדיין קטנה למדי, אך גדולה ממה שנרצה לחשב ביד.
# Define our small test matrix
test_matrix = np.array(
[
[4, -1, 0, 1, 0],
[-1, 4, -1, 2, 1],
[0, -1, 4, 3, 3],
[1, 2, 3, 4, 0],
[0, 1, 3, 0, 4],
]
)
# Give the test matrix and an initial guess as arguments in the function defined above.
# Calculate outputs.
test_ks, test_Hs, test_eigs, text_k_tot_times = krylov_full_build(
np.array([0.5, 0.5, 0, 0.5, 0.5]), test_matrix
)
אפשר לאמת את הפונקציות שלנו על ידי בדיקה שבשלב האחרון (כשמרחב Krylov הוא המרחב הווקטורי המלא של המטריצה המקורית) הערכים העצמיים שנתקבלו מתאימים בדיוק לאלה שהתקבלו מאלכסון מספרי מדויק:
print(np.linalg.eig(test_matrix).eigenvalues)
print(test_eigs[len(test_matrix) - 1])
[-1.36956923 8.43756009 2.9040308 5.34436028 4.68361806]
[-1.36956923 8.43756009 2.9040308 4.68361806 5.34436028]
זה הצליח. כמובן, מה שחשוב באמת הוא כמה טובה ההקרבה שלנו כפונקציה של ממד תת-מרחב Krylov. מכיוון שלרוב אנחנו מחפשים מצבי יסוד וערכים עצמיים מינימליים אחרים (ומסיבות אלגבריות נוספות שיוסברו להלן), בואו נסתכל על האומדן שלנו לערך העצמי הנמוך ביותר כפונקציה של ממד תת-מרחב Krylov. כלומר:
def errors(matrix, krylov_eigs):
targ_min = min(np.linalg.eig(matrix).eigenvalues)
err = []
for i in range(len(matrix)):
err.append(min(krylov_eigs[i]) - targ_min)
return err
import matplotlib.pyplot as plt
krylov_error = errors(test_matrix, test_eigs)
plt.plot(krylov_error)
plt.axhline(y=0, color="red", linestyle="--") # Add dashed red line at y=0
plt.xlabel("Order of Krylov subspace") # Add x-axis label
plt.ylabel("Error in minimum eigenvalue") # Add y-axis label
plt.show()
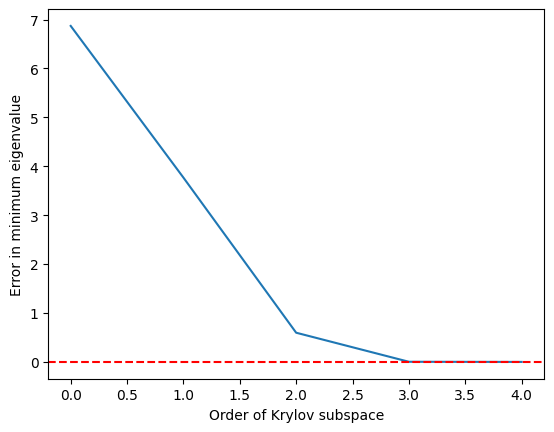
אנחנו רואים שהערך העצמי המינימלי מגיע לדיוק סביר ברגע שתת-מרחב Krylov גדל ל- ומדויק לחלוטין ב-
2.2 קנה המידה של הזמן עם ממד המטריצה
בואו נשכנע את עצמנו שלשיטת Krylov יש יתרון על פני פותרי ערכים עצמיים מספריים מדויקים, בדרך הבאה:
- בונים מטריצות אקראיות (לא דלילות — לא היישום האידיאלי עבור KQD)
- קובעים ערכים עצמיים בשתי שיטות: ישירות באמצעות NumPy ובאמצעות תת-מרחב Krylov.
- בוחרים סף דיוק לערכים העצמיים שלנו, לפני שנקבל את אומדני Krylov.
- משווים את זמן הריצה הנדרש לפתרון בשתי הדרכים.
הסתייגויות: כפי שנדון בפירוט להלן, אלכסון קוונטי של Krylov מתאים בעיקר לאופרטורים שייצוגי המטריצה שלהם דלילים ו/או ניתנים לכתיבה תוך שימוש במספר קטן של קבוצות אופרטורי Pauli מתחלפים. המטריצות האקראיות שאנו משתמשים בהן כאן אינן מתאימות לתיאור זה. הן שימושיות רק לבחינת הקנה-מידה שבו שיטות Krylov קלאסיות עשויות להיות מועילות. שנית, בשימוש בשיטת Krylov נחשב ערכים עצמיים בעזרת תת-מרחבות Krylov בגדלים שונים. נדווח על הזמן הנדרש עבור תת-מרחב Krylov בממד המינימלי שמשיג את הדיוק הנדרש עבור ערך ה-eigenstate הבסיסי. שוב, זה קצת שונה מפתרון בעיה שאינה בת-פתרון עבור פותרי ערכים עצמיים מדויקים, מכיוון שאנו משתמשים בפתרון המדויק כדי להעריך את הממד הנדרש.
נתחיל ביצירת קבוצת המטריצות האקראיות שלנו.
import numpy as np
# Set the random seed
np.random.seed(42)
# how many random matrices will we make
num_matrix = 200
matrices = []
for m in range(1, num_matrix):
matrices.append(np.random.rand(m, m))
עכשיו נאלכסן כל מטריצה ישירות באמצעות numpy. נחשב את הזמן הנדרש לאלכסון להשוואה מאוחרת יותר.
matrix_numpy_times = []
matrix_numpy_eigs = []
for mm in range(num_matrix - 1):
t0 = time_mus()
matrix_numpy_eigs.append(min(np.linalg.eig(matrices[mm]).eigenvalues))
matrix_numpy_times.append(time_mus() - t0)
plt.plot(matrix_numpy_times)
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()
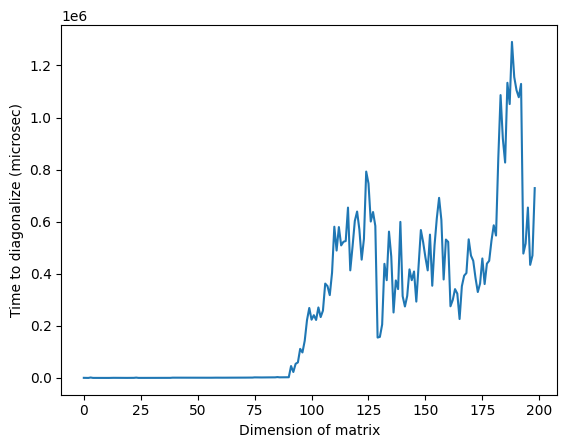
שימו לב שבתמונה למעלה, הזמן הגבוה באופן חריג סביב ממד 125 עשוי לנבוע מהאופי האקראי של המטריצות או מהיישום על המעבד הקלאסי שנעשה בו שימוש, אך הוא אינו ניתן לשחזור. הרצה מחדש של הקוד תניב פרופיל שונה עם פסגות חריגות שונות.
עכשיו עבור כל מטריצה נבנה תת-מרחב Krylov ונחשב ערכים עצמיים בשלבים. בכל שלב נבדוק אם הערך העצמי הנמוך ביותר התקבל בתוך השגיאה המוחלטת שציינו. תת-המרחב שמניב לראשונה ערכים עצמיים בתוך השגיאה הנדרשת הוא זה שנרשום עבורו את זמני החישוב. הרצת תא זה עשויה לקחת כמה דקות, בהתאם למהירות המעבד. אפשר לדלג על הביצוע או להקטין את הממד המקסימלי של המטריצות המאולכסנות. בחינת התוצאות המחושבות מראש מספיקה.
# Choose the absolute error you can tolerate, and make a list for tracking the Krylov subspace size
# at which that error is achieved.
abserr = 0.05
accept_subspace_size = []
# Lists to store total time spent on the Krylov method, and the subset of that time spent on
# diagonalizing the projected matrix.
matrix_krylov_tot_times = []
matrix_krylov_dim = []
# Step through all our random matrices
for mm in range(0, num_matrix - 1):
test_ks, test_Hs, test_eigs, test_k_tot_times = krylov_full_build(
np.ones(len(matrices[mm])), matrices[mm]
)
# We have not yet found a Krylov subspace that produces our minimum eigenvalue to
# within the required error.
found = 0
for j in range(0, len(matrices[mm]) - 1):
# If we still haven't found the desired subspace...
if found == 0:
# ...but if this one satisfies the requirement, then record everything
if (
abs((min(test_eigs[j]) - matrix_numpy_eigs[mm]) / matrix_numpy_eigs[mm])
< abserr
):
accept_subspace_size.append(j)
matrix_krylov_tot_times.append(test_k_tot_times[j])
matrix_krylov_dim.append(mm)
found = 1
בואו נשרטט את הזמנים שקיבלנו לשתי השיטות הללו להשוואה:
plt.plot(matrix_numpy_times, color="blue")
plt.plot(matrix_krylov_dim, matrix_krylov_tot_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()

אלה הזמנים בפועל הנדרשים, אך לצורכי הדיון, בואו נחליק את העקומות הללו על ידי ממוצע על פני כמה נקודות/ממדי מטריצה סמוכים. זה נעשה להלן:
smooth_numpy_times = []
smooth_krylov_times = []
# Choose the number of adjacent points over which to average forward;
# the same will be used backward.
smooth_steps = 10
# We will do this smoothing for all points/matrix dimensions
for i in range(len(matrix_krylov_tot_times)):
# Ensure we don't exceed the boundaries of our lists
start = max(0, i - smooth_steps)
end = min(len(matrix_krylov_tot_times) - 1, i + smooth_steps)
# Dummy variables for accumulating an average over adjacent points. This is done for both Krylov
# and the NumPy calculations.
smooth_count = 0
smooth_numpy_sum = 0
smooth_krylov_sum = 0
for j in range(start, end):
smooth_numpy_sum = smooth_numpy_sum + matrix_numpy_times[j]
smooth_krylov_sum = smooth_krylov_sum + matrix_krylov_tot_times[j]
smooth_count = smooth_count + 1
# Appending the averaged adjacent values to our new smooth lists
smooth_numpy_times.append(smooth_numpy_sum / smooth_count)
smooth_krylov_times.append(smooth_krylov_sum / smooth_count)
plt.plot(smooth_numpy_times, color="blue")
plt.plot(smooth_krylov_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (smoothed, microsec)") # Add y-axis label
plt.show()

שימו לב שהזמן הנדרש לבניית תת-מרחב Krylov עולה בתחילה על הזמן הנדרש לאלכסון המלא של numpy. אך ככל שגודל המטריצה גדל, שיטת Krylov הופכת לאדוונטגית. זה נכון גם אם נוריד את השגיאה המקובלת, אך היתרון מתחיל בממד מטריצה גדול יותר. כדאי לנתח זאת לעומק.
המורכבות הזמנית של האלכסון המספרי היא (עם שונות מסוימת בין האלגוריתמים). המורכבות הזמנית של יצירת בסיס אורתונורמלי של ווקטורים היא גם . לכן היתרון של שיטת Krylov אינו קשור לשימוש ב- בסיס אורתונורמלי כלשהו, אלא לשימוש בבסיס אורתונורמלי ספציפי שמוציא ביעילות את הערכים העצמיים המעניינים. כבר ראינו זאת מהסקיצה של ההוכחה בחלק הראשון של השיעור, וזה קריטי לערבויות ההתכנסות בשיטות Krylov.
בואו נסכם את ההתקדמות שלנו עד כה:
- עבור מטריצות גדולות מאוד, שיטת תת-מרחב Krylov עשויה לתת ערכים עצמיים משוערים בתוך סבילויות נדרשות מהר יותר מאלגוריתמי האלכסון המסורתיים.
- עבור מטריצות גדולות כאלה, יצירת תת-מרחב Krylov היא החלק הגוזל זמן הרב ביותר בשיטת תת-מרחב Krylov.
- לכן, דרך יעילה ליצירת תת-מרחב Krylov תהיה בעלת ערך רב.
וכאן לבסוף נכנס המחשב הקוונטי לתמונה.
בדוק את ההבנה שלך
ראה בגרף המוחלק של זמני האלכסון מול ממד המטריצה למעלה.
(א) באיזה ממד מטריצה בערך שיטת Krylov הפכה למהירה יותר, לפי הגרף הזה?
(ב) אילו היבטים של החישוב יכולים לשנות את הממד שבו שיטת Krylov הופכת למהירה יותר?
Answer
(א) התשובות עשויות להשתנות אם תריץ מחדש את החישוב, אך שיטת Krylov הופכת מהירה יותר בממד של כ-80-85.
(ב) ישנן תשובות אפשריות רבות. גורמים חשובים אחדים הם הדיוק הנדרש ודלילות המטריצות המאולכסנות.
3. קריילוב דרך אבולוציית זמן
כל מה שתיארנו עד כה ניתן לביצוע קלאסי. אז איך ומתי נשתמש במחשב קוונטי? עבור מטריצות גדולות מאוד, שיטת קריילוב עלולה לדרוש זמני חישוב ארוכים וכמויות זיכרון גדולות. הזמן הנדרש לפעולת המטריצה של על גדל כמו במקרה הגרוע ביותר. אפילו כפל של מטריצות דלילות בווקטור (המקרה הטיפוסי עבור פותרי קריילוב קלאסיים) בעל מורכבות זמן שמשתנה כמו . זה נעשה עבור כל ווקטור שנרצה בתת-המרחב שלנו. ממד תת-המרחב הוא בדרך כלל לא חלק משמעותי מ-, ולרוב משתנה כמו . כך שיצירת כל הווקטורים גדלה כמו במקרה הגרוע ביותר. אמנם ישנם שלבים נוספים כמו אורתוגונליזציה, אך זהו הסקלינג הדומיננטי שכדאי לזכור.
מחשוב קוונטי מאפשר לנו לשנות אילו מאפייני הבעיה קובעים את הסקלינג של הזמן והמשאבים הנדרשים. במקום תלות בגודל המטריצה בכל מקום, נראה דברים כמו מספר הירויות ומספר איברי הפאולי שאינם מתחלפים, שמרכיבים את ההמילטוניאן. בואו נחקור איך זה עובד.
3.1 אבולוציית זמן
נזכיר שהאופרטור שמבצע אבולוציית זמן למצב קוונטי הוא (ומאוד נפוץ, בייחוד במחשוב קוונטי, להשמיט את מהסימון). דרך אחת להבין ואפילו לממש פונקציה אקספוננציאלית כזו של אופרטור היא להסתכל על פיתוח טיילור שלה. שימו לב שהפעולה הזאת על ווקטור התחלתי מניבה סכום של איברים עם חזקות עולות של המופעלות על המצב ההתחלתי. נראה שאפשר פשוט לבנות את תת-מרחב קריילוב שלנו על ידי אבולוציית זמן של מצב הניחוש ההתחלתי שלנו!
הסייג הוא במימוש אבולוציית הזמן על מחשב קוונטי אמיתי. רבים מהאיברים בהמילטוניאן לא יתחלפו אחד עם השני. כך שבעוד שאופרטורים אקספוננציאלים פשוטים כמו מתאימים ל-Circuit פשוטים, המילטוניאנים כלליים לא. ומכיוון שהם מכילים איברים שאינם מתחלפים, אי אפשר פשוט לפרק את האקספוננט למכפלה של אקספוננטים פשוטים, כפי שניתן לעשות עם מספרים.
כך שזה לא טריוויאלי, אבל זהו תהליך שנחקר היטב במחשוב קוונטי. אנחנו מבצעים אבולוציית זמן על מחשבים קוונטיים באמצעות תהליך הנקרא טרוטריזציה, שבפני עצמו הוא נושא עשיר[10]. אבל ברמה גבוהה מאוד, על ידי פיצול אבולוציית הזמן לצעדים קטנים מאוד, נגיד צעדים בגודל , אנחנו מגבילים את השפעות אי-ההתחלפות של האיברים.
כאשר .
בואו נקרא לתת-מרחב קריילוב מסדר r שיצרנו בהקשר הקלאסי באמצעות חזקות של H ישירות "תת-מרחב קריילוב כוחות".
כעת אנחנו יוצרים מרחב דומה באמצעות אופרטור האבולוציה הוניטרית ; נתייחס אליו כ"תת-מרחב קריילוב יוניטרי" . תת-מרחב קריילוב הכוחות שאנו משתמשים בו קלאסית אינו יכול להיווצר ישירות על מחשב קוונטי מאחר ש- אינו אופרטור יוניטרי. ניתן להראות ששימוש בתת-מרחב קריילוב היוניטרי נותן ערבויות התכנסות דומות לאלו של תת-מרחב קריילוב הכוחות, כלומר שגיאת מצב היסוד מתכנסת ביעילות כל עוד למצב ההתחלתי יש חפיפה עם מצב היסוד האמיתי שאינה נעלמת באופן אקספוננציאלי, וכל עוד קיים פער מספיק בין ערכי העצם. ראו Ref [1] לדיון מדויק יותר על התכנסות.
כאן, חזקות של הופכות לצעדי זמן שונים (החזקה ה- של היא צעד קדימה בזמן ). אפשר לסמן את איבר תת-המרחב שעבר אבולוציית זמן כוללת כ-.
אנחנו יכולים להטיל את ההמילטוניאן H על תת-מרחב קריילוב היוניטרי, . במילים אחרות, אנחנו מחשבים כל איבר מטריצה של בבסיס . נתייחס למטריצה המוטלת הזו כ-.
3.2 איך לממש על מחשב קוונטי
איברי המטריצה של ניתנים על ידי ערכי הציפייה , שניתן לאמוד אותם באמצעות המחשב הקוונטי. זכרו ש- ניתן לכתיבה כסכום של אופרטורי פאולי על qubit-ים שונים, ושלא כל אופרטורי הפאולי ניתנים למדידה בו-זמנית. אנחנו יכולים למיין את איברי הפאולי לקבוצות של איברים מתחלפים, ולמדוד את כולם בבת אחת. אבל אולי נצטרך קבוצות רבות כאלה כדי לכסות את כל האיברים. לכן מספר קבוצות ההתחלפות הדיסקרטיות שבהן ניתן לחלק את האיברים, , הופך לחשוב.
כאן הוא מחרוזת פאולי מהצורה או קבוצה של מחרוזות פאולי כאלה שמתחלפות אחת עם השנייה. בהינתן שאנו יכולים לכתוב את כסכום כזה של אופרטורים הניתנים למדידה, הביטויים הבאים לאיברי המטריצה של ניתנים למימוש באמצעות ה-Estimator הפרימיטיבי של Qiskit Runtime.
כאשר הם הווקטורים של תת-מרחב קריילוב היוניטרי ו- הם כפולות של צעד הזמן שנבחר. על מחשב קוונטי, החישוב של כל איבר מטריצה ניתן לביצוע עם כל אלגוריתם שמאפשר לנו לקבל חפיפה בין מצבים קוונטיים. בשיעור זה נתמקד במבחן הדמארד. בהינתן שלתת-מרחב יש ממד , להמילטוניאן המוטל לתת-המרחב יהיו ממדים . כשהממד קטן מספיק (בדרך כלל מספיק כדי לקבל התכנסות של הערכות ערכי העצם) אנחנו יכולים אז לאלכסן בקלות את ההמילטוניאן המוטל קלאסית. עם זאת, אי אפשר לאלכסן ישירות את בגלל אי-אורתוגונליות הווקטורים של תת-מרחב קריילוב. נצטרך למדוד את החפיפות שלהם ולבנות מטריצה
זה מאפשר לנו לפתור את בעיית ערכי העצם במרחב שאינו אורתוגונלי (הנקראת גם בעיית ערכי עצם מוכללת)
לאחר מכן ניתן לקבל הערכות של ערכי העצם וווקטורי העצם של על ידי בחינת הפתרונות של בעיית ערכי העצם המוכללת הזו. לדוגמה, הערכת אנרגיית מצב היסוד מתקבלת על ידי לקיחת ערך העצם הקטן ביותר ומצב היסוד מווקטור העצם המתאים . המקדמים ב- קובעים את התרומה של הווקטורים השונים שפורשים את .
בעיית ערכי עצם מוכללת
למה אי אפשר פשוט לאלכסן את ? מאחר ש- מכיל את המידע על גיאומטריית בסיס קריילוב (שהוא לא-אורתוגונלי בכל המקרים פרט למקרים מיוחדים מאוד), בפני עצמו לא מתאר הטלה של ההמילטוניאן המלא, לכן לערכי העצם שלו אין יחס מיוחד לאלה של ההמילטוניאן המלא — הם יכולים להיות ערכים אקראיים כלשהם. פתרון בעיית ערכי העצם המוכללת נדרש כדי לקבל את ערכי העצם ווקטורי העצם המקורבים המתאימים להטלה של ההמילטוניאן המלא למרחב קריילוב.
האיור מראה ייצוג Circuit של מבחן הדמארד המשונה, שיטה המשמשת לחישוב החפיפה בין מצבים קוונטיים שונים. עבור כל איבר מטריצה , מבחן הדמארד בין המצב , מבוצע. זה מודגש באיור על ידי ערכת הצבעים לאיברי המטריצה ופעולות , המתאימות. כך, נדרש קבוצה של מבחני הדמארד עבור כל הצירופים האפשריים של ווקטורי תת-מרחב קריילוב כדי לחשב את כל איברי המטריצה של ההמילטוניאן המוטל . החוט העליון ב-Circuit של מבחן הדמארד הוא qubit עזר הנמדד בבסיס X או Y, ערך הציפייה שלו קובע את ערך החפיפה בין המצבים. החוט התחתון מייצג את כל ה-Qubit-ים של ההמילטוניאן של המערכת. פעולת מכינה את ה-Qubit של המערכת במצב בהתאם למצב ה-Qubit העזר (באופן דומה עבור ) ופעולת מייצגת פירוק פאולי של ההמילטוניאן של המערכת . המימוש של זה על מחשב קוונטי מוצג בפירוט רב יותר להלן.
4. אלכסון קוונטי של קריילוב על מחשב קוונטי
כעת נממש אלכסון קוונטי של קריילוב על מחשב קוונטי אמיתי. בואו נתחיל בייבוא כמה חבילות שימושיות.
import numpy as np
import scipy as sp
import matplotlib.pylab as plt
from typing import Union, List
import warnings
from qiskit.quantum_info import SparsePauliOp, Pauli
from qiskit.circuit import Parameter
from qiskit import QuantumCircuit, QuantumRegister
from qiskit.circuit.library import PauliEvolutionGate
from qiskit.synthesis import LieTrotter
# from qiskit.providers.fake_provider import Fake20QV1
from qiskit_ibm_runtime import QiskitRuntimeService, EstimatorV2 as Estimator, Batch
import itertools as it
warnings.filterwarnings("ignore")
אנחנו מגדירים את הפונקציה למטה כדי לפתור את בעיית ערכי העצם המוכללת שהסברנו זה עתה.
def solve_regularized_gen_eig(
h: np.ndarray,
s: np.ndarray,
threshold: float,
k: int = 1,
return_dimn: bool = False,
) -> Union[float, List[float]]:
"""
Method for solving the generalized eigenvalue problem with regularization
Args:
h (numpy.ndarray):
The effective representation of the matrix in our Krylov subspace
s (numpy.ndarray):
The matrix of overlaps between vectors of our Krylov subspace
threshold (float):
Cut-off value for the eigenvalue of s
k (int):
Number of eigenvalues to return
return_dimn (bool):
Whether to return the size of the regularized subspace
Returns:
lowest k-eigenvalue(s) that are the solution of the regularized generalized eigenvalue problem
"""
s_vals, s_vecs = sp.linalg.eigh(s)
s_vecs = s_vecs.T
good_vecs = np.array([vec for val, vec in zip(s_vals, s_vecs) if val > threshold])
h_reg = good_vecs.conj() @ h @ good_vecs.T
s_reg = good_vecs.conj() @ s @ good_vecs.T
if k == 1:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][0], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][0]
else:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][:k], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][:k]
לפחות בבנצ'מרקינג ראשוני, שימושי לדעת פתרון קלאסי מדויק כדי לבדוק התנהגות התכנסות. הפונקציה למטה מחשבת את אנרגיית מצב היסוד של המילטוניאן, תוך שימוש בהמילטוניאן ובמספר ה-Qubit-ים כארגומנטים.
def single_particle_gs(H_op, n_qubits):
"""
Find the ground state of the single particle(excitation) sector
"""
H_x = []
for p, coeff in H_op.to_list():
H_x.append(set([i for i, v in enumerate(Pauli(p).x) if v]))
H_z = []
for p, coeff in H_op.to_list():
H_z.append(set([i for i, v in enumerate(Pauli(p).z) if v]))
H_c = H_op.coeffs
print("n_sys_qubits", n_qubits)
n_exc = 1
sub_dimn = int(sp.special.comb(n_qubits + 1, n_exc))
print("n_exc", n_exc, ", subspace dimension", sub_dimn)
few_particle_H = np.zeros((sub_dimn, sub_dimn), dtype=complex)
sparse_vecs = [
set(vec) for vec in it.combinations(range(n_qubits + 1), r=n_exc)
] # list all of the possible sets of n_exc indices of 1s in n_exc-particle states
m = 0
for i, i_set in enumerate(sparse_vecs):
for j, j_set in enumerate(sparse_vecs):
m += 1
if len(i_set.symmetric_difference(j_set)) <= 2:
for p_x, p_z, coeff in zip(H_x, H_z, H_c):
if i_set.symmetric_difference(j_set) == p_x:
sgn = ((-1j) ** len(p_x.intersection(p_z))) * (
(-1) ** len(i_set.intersection(p_z))
)
else:
sgn = 0
few_particle_H[i, j] += sgn * coeff
gs_en = min(np.linalg.eigvalsh(few_particle_H))
print("single particle ground state energy: ", gs_en)
return gs_en
4.1 שלב 1: מיפוי הבעיה למעגלים קוונטיים ואופרטורים
כעת נגדיר המילטוניאן. הוא שונה מהפונקציה שהגדרנו למעלה — אותה פונקציה מקבלת המילטוניאן כארגומנט ומחזירה רק את מצב היסוד, וזאת בצורה קלאסית. ההמילטוניאן שנגדיר כאן קובע את רמות האנרגיה של כל מצבי האנרגיה העצמיים, וניתן לבנות אותו באמצעות אופרטורי פאולי ולממש אותו על מחשב קוונטי.
אנחנו בוחרים המילטוניאן המתאים לשרשרת ספינים שיכולים לקבל כל כיוון במרחב, הנקראת "שרשרת היזנברג". אנחנו מניחים שהספין ה- מושפע רק משכניו הקרובים (ספינים ו-) ולא משכנים רחוקים יותר. אנחנו גם מאפשרים את האפשרות שהאינטראקציה בין הספינים שונה כאשר הם מצביעים לאורך צירים שונים. אסימטריה זו מתעוררת לעיתים, למשל, בשל מבנה סריג הגביש שבו הספינים משובצים.
# Define problem Hamiltonian.
n_qubits = 10
# coupling strength for XX, YY, and ZZ interactions
JX = 1
JY = 3
JZ = 2
# Define the Hamiltonian:
H_int = [["I"] * n_qubits for _ in range(3 * (n_qubits - 1))]
for i in range(n_qubits - 1):
H_int[i][i] = "Z"
H_int[i][i + 1] = "Z"
for i in range(n_qubits - 1):
H_int[n_qubits - 1 + i][i] = "X"
H_int[n_qubits - 1 + i][i + 1] = "X"
for i in range(n_qubits - 1):
H_int[2 * (n_qubits - 1) + i][i] = "Y"
H_int[2 * (n_qubits - 1) + i][i + 1] = "Y"
H_int = ["".join(term) for term in H_int]
H_tot = [
(term, JZ)
if term.count("Z") == 2
else (term, JY)
if term.count("Y") == 2
else (term, JX)
for term in H_int
]
# Get operator
H_op = SparsePauliOp.from_list(H_tot)
print(H_tot)
[('ZZIIIIIIII', 2), ('IZZIIIIIII', 2), ('IIZZIIIIII', 2), ('IIIZZIIIII', 2), ('IIIIZZIIII', 2), ('IIIIIZZIII', 2), ('IIIIIIZZII', 2), ('IIIIIIIZZI', 2), ('IIIIIIIIZZ', 2), ('XXIIIIIIII', 1), ('IXXIIIIIII', 1), ('IIXXIIIIII', 1), ('IIIXXIIIII', 1), ('IIIIXXIIII', 1), ('IIIIIXXIII', 1), ('IIIIIIXXII', 1), ('IIIIIIIXXI', 1), ('IIIIIIIIXX', 1), ('YYIIIIIIII', 3), ('IYYIIIIIII', 3), ('IIYYIIIIII', 3), ('IIIYYIIIII', 3), ('IIIIYYIIII', 3), ('IIIIIYYIII', 3), ('IIIIIIYYII', 3), ('IIIIIIIYYI', 3), ('IIIIIIIIYY', 3)]
הקוד הבא מגביל את ההמילטוניאן למצבי חלקיק יחיד, ומשתמש בנורמה הספקטרלית כדי לקבוע גודל טוב לצעד הזמן שלנו. אנחנו בוחרים ערך היוריסטי לצעד הזמן dt (בהתבסס על חסמים עליונים לנורמת ההמילטוניאן). הפניה [9] הראתה שצעד זמן קטן מספיק הוא , ועדיף עד נקודה מסוימת להעריך פחות ממה שצריך מאשר יותר, שכן הערכת יתר יכולה לאפשר לתרומות ממצבים בעלי אנרגיה גבוהה להשחית אפילו את המצב האופטימלי במרחב קרילוב. מצד שני, בחירת קטן מדי מובילה לקונדיציה גרועה יותר של תת-המרחב של קרילוב, מאחר שוקטורי בסיס קרילוב שונים פחות מצעד לצעד.
# Get Hamiltonian restricted to single-particle states
single_particle_H = np.zeros((n_qubits, n_qubits))
for i in range(n_qubits):
for j in range(i + 1):
for p, coeff in H_op.to_list():
p_x = Pauli(p).x
p_z = Pauli(p).z
if all(p_x[k] == ((i == k) + (j == k)) % 2 for k in range(n_qubits)):
sgn = ((-1j) ** sum(p_z[k] and p_x[k] for k in range(n_qubits))) * (
(-1) ** p_z[i]
)
else:
sgn = 0
single_particle_H[i, j] += sgn * coeff
for i in range(n_qubits):
for j in range(i + 1, n_qubits):
single_particle_H[i, j] = np.conj(single_particle_H[j, i])
# Set dt according to spectral norm
dt = np.pi / np.linalg.norm(single_particle_H, ord=2)
dt
np.float64(0.17453292519943295)
אנחנו מציינים את מספר צעדי הטרוטר לשימוש בהתפתחות הזמן. כמו כן אנחנו מציינים מימד קרילוב מקסימלי של 4. מימד קרילוב זה אינו גדול מספיק ליישומים ריאליסטיים. אך הוא מספיק לדוגמה זו. יתרה מכך, נבדוק התכנסות גם במימדים קטנים יותר. נחקור שיטות בשיעורים מאוחרים יותר שיאפשרו לנו להרחיב את ההמילטוניאנים שלנו ולהטיל אותם על תת-מרחבים גדולים יותר.
# Set parameters for quantum Krylov algorithm
krylov_dim = 4 # size of krylov subspace
num_trotter_steps = 4
dt_circ = dt / num_trotter_steps
הכנת מצב
בחרו מצב ייחוס שיש לו חפיפה כלשהי עם מצב היסוד. עבור המילטוניאן זה, אנחנו משתמשים במצב עם עירור ב-Qubit האמצעי כמצב הייחוס שלנו.
qc_state_prep = QuantumCircuit(n_qubits)
qc_state_prep.x(int(n_qubits / 2) + 1)
qc_state_prep.draw("mpl", scale=0.5)

התפתחות זמן
ניתן לממש את אופרטור התפתחות הזמן הנוצר על ידי המילטוניאן נתון: באמצעות קירוב ליי-טרוטר. לשם הפשטות, אנחנו משתמשים ב-PauliEvolutionGate המובנה במעגל התפתחות הזמן. התחביר הכללי לכך הוא כדלקמן.
t = Parameter("t")
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=t, synthesis=LieTrotter(reps=num_trotter_steps)
)
qr = QuantumRegister(n_qubits)
qc_evol = QuantumCircuit(qr)
qc_evol.append(evol_gate, qargs=qr)
<qiskit.circuit.instructionset.InstructionSet at 0x7ccaa4664250>
נשתמש בגרסה של זה להלן במבחן הדמארד, אך נתקדם בצעדים של .
מבחן הדמארד
נזכור שאנו רוצים לחשב את איברי המטריצה של ואת מטריצת גרם באמצעות מבחן הדמארד. בואו נסקור כיצד זה עובד בהקשר זה, תוך התמקדות תחילה בבניית התהליך הכולל מתואר גרפית להלן. שכבות בלוקי הכנת המצב הצבעוניות משמשות כתזכורת שתהליך זה מתבצע עבור כל הצירופים של ו- בתת-המרחב שלנו.
מצבי המערכת בשלבים המסומנים הם:
כאן הוא איבר פאולי בפירוק ההמילטוניאן (שימו לב שהוא לא יכול להיות צירוף לינארי של כמה איברי פאולי מתחלפים, שכן זה לא יהיה יוניטרי — קיבוץ אפשרי באמצעות בנייה שונה שנציג בהמשך) , הן פעולות מבוקרות המכינות את הוקטורים , של מרחב קרילוב היוניטרי, כאשר . החלת מדידות של ו- על מעגל זה מחשבת את החלקים הממשיים והמדומים, בהתאמה, של איברי המטריצה שאנו זקוקים להם.
החל מהשלב 4 לעיל, הפעל את שער הדמארד על ה-Qubit האפסי.
לאחר מכן מדדו או .
מהזהות . באופן דומה, מדידת נותנת
בהוספת שלבים אלה להתפתחות הזמן שהגדרנו קודם לכן, נכתוב את הדברים הבאים.
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
## Create the time-evo op dagger circuit
evol_gate_d = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
evol_gate_d = evol_gate_d.inverse()
# Put pieces together
qc_reg = QuantumRegister(n_qubits)
qc_temp = QuantumCircuit(qc_reg)
qc_temp.compose(qc_state_prep, inplace=True)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate, qargs=qc_reg)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate_d, qargs=qc_reg)
qc_temp.compose(qc_state_prep.inverse(), inplace=True)
# Create controlled version of the circuit
controlled_U = qc_temp.to_gate().control(1)
# Create hadamard test circuit for real part
qr = QuantumRegister(n_qubits + 1)
qc_real = QuantumCircuit(qr)
qc_real.h(0)
qc_real.append(controlled_U, list(range(n_qubits + 1)))
qc_real.h(0)
print("Circuit for calculating the real part of the overlap in S via Hadamard test")
qc_real.draw("mpl", fold=-1, scale=0.5)
Circuit for calculating the real part of the overlap in S via Hadamard test

כבר הזהרנו לגבי העומק הכרוך במעגלי טרוטר. ביצוע מבחן הדמארד בתנאים אלה יכול לייצר מעגל עמוק אף יותר, במיוחד לאחר שנפרק לשערים מקומיים. זה יגדל עוד יותר אם נתחשב בטופולוגיה של המכשיר. לכן, לפני שנשתמש בכל זמן במחשב הקוונטי, כדאי לבדוק את עומק דו-ה-Qubit של המעגל שלנו.
print(
"Number of layers of 2Q operations",
qc_real.decompose(reps=2).depth(lambda x: x[0].num_qubits == 2),
)
Number of layers of 2Q operations 14401
מעגל בעומק כזה אינו יכול להחזיר תוצאות שמישות במחשבים קוונטיים מודרניים. אם אנחנו רוצים לבנות את ו- אנחנו זקוקים לדרך טובה יותר. זו הסיבה למבחן הדמארד היעיל שיוצג להלן.
4. 2 שלב 2. אופטימיזציה של מעגלים ואופרטורים לחומרת היעד
מבחן הדאמר היעיל
ניתן לאפטם את המעגלים העמוקים של מבחן הדאמר שקיבלנו על ידי הכנסת כמה קירובים והסתמכות על הנחות מסוימות לגבי הה-המילטוניאן של המודל. לדוגמה, נסתכל על המעגל הבא למבחן הדאמר:
נניח שאנחנו יכולים לחשב קלאסית את , ערך העצמי של תחת ההמילטוניאן . הנחה זו מתקיימת כאשר ההמילטוניאן שומר על הסימטריה U(1). למרות שזה עשוי להישמע כהנחה חזקה, ישנם מקרים רבים בהם ניתן להניח בבטחה שקיימת מצב ריק (במקרה זה הוא ממופה למצב ) שאינו מושפע מפעולת ההמילטוניאן. זה נכון לדוגמה עבור המילטוניאנים של כימיה המתארים מולקולות יציבות (שבהן מספר האלקטרונים נשמר). בהינתן שהשער מכין את מצב הייחוס הרצוי , לדוגמה, כדי להכין את מצב HF לכימיה יהיה מכפלה של NOTs חד-קיוביטיים, כך ש-controlled- הוא פשוט מכפלה של CNOTs. אז המעגל לעיל מממש את המצב הבא לפני המדידה:
כאשר השתמשנו בהזזת הפאזה הניתנת לסימולציה קלאסית משלב 2 לשלב 3. לכן ערכי הציפייה הם
בעזרת הנחות אלה הצלחנו לכתוב את ערכי הציפייה של האופרטורים הרלוונטיים עם פחות פעולות מבוקרות. למעשה, אנחנו צריכים לממש רק את הכנת המצב המבוקרת ולא אבולוציות זמן מבוקרות. ניסוח מחדש של החישוב שלנו כפי שלעיל יאפשר לנו להפחית באופן משמעותי את העומק של המעגלים המתקבלים.
שים לב שכבונוס, מכיוון שאופרטור פאולי מופיע כעת כמדידה בסוף המעגל במקום כשער מבוקר באמצע, ניתן למדוד אותו לצד אופרטורי פאולי מתחלפים אחרים כפי הפירוק שניתן לעיל.
פירוק אופרטור האבולוציה בזמן עם פירוק Trotter
במקום לממש את אופרטור האבולוציה בזמן במדויק, אנחנו יכולים להשתמש בפירוק Trotter כדי לממש קירוב שלו. חזרה מספר פעמים על פירוק Trotter מסדר מסוים מאפשרת לנו להפחית עוד יותר את השגיאה הנובעת מהקירוב. בהמשך, אנחנו בונים ישירות את המימוש של Trotter בדרך הכי יעילה לגרף האינטראקציה של ההמילטוניאן שאנחנו בוחנים (אינטראקציות של שכנים קרובים בלבד). בפועל אנחנו מכניסים סיבובי פאולי , , עם עוצמות צימוד ו- וזווית פרמטרית , המתאימים למימוש המקורב של . בהתחשב בהבדל בהגדרה של סיבובי הפאולי ואבולוציית הזמן שאנחנו מנסים לממש, נצטרך להשתמש בפרמטר כדי להשיג אבולוציית זמן של . בנוסף, אנחנו הופכים את סדר הפעולות עבור מספר אי-זוגי של חזרות של צעדי Trotter, שזה שקול פונקציונלית אך מאפשר לסנתז פעולות סמוכות ביחידה אחת. זה נותן מעגל הרבה יותר רדוד מזה שמתקבל עם הפונקציונליות הגנרית PauliEvolutionGate().
t = Parameter("t")
# Create instruction for rotation about XX+YY-ZZ:
Rxyz_circ = QuantumCircuit(2)
Rxyz_circ.rxx(2 * JX * t, 0, 1)
Rxyz_circ.ryy(2 * JY * t, 0, 1)
Rxyz_circ.rzz(2 * JZ * t, 0, 1)
Rxyz_instr = Rxyz_circ.to_instruction(label="R J_x XX + J_y YY + J_z ZZ")
interaction_list = [
[[i, i + 1] for i in range(0, n_qubits - 1, 2)],
[[i, i + 1] for i in range(1, n_qubits - 1, 2)],
] # linear chain
qr = QuantumRegister(n_qubits)
trotter_step_circ = QuantumCircuit(qr)
for i, color in enumerate(interaction_list):
for interaction in color:
trotter_step_circ.append(Rxyz_instr, interaction)
if i < len(interaction_list) - 1:
trotter_step_circ.barrier()
reverse_trotter_step_circ = trotter_step_circ.reverse_ops()
qc_evol = QuantumCircuit(qr)
for step in range(num_trotter_steps):
if step % 2 == 0:
qc_evol = qc_evol.compose(trotter_step_circ)
else:
qc_evol = qc_evol.compose(reverse_trotter_step_circ)
qc_evol.decompose().draw("mpl", fold=-1, scale=0.5)
אנחנו מכינים מצב ראשוני מחדש עבור מבחן הדאמר היעיל הזה.
control = 0
excitation = int(n_qubits / 2) + 1
controlled_state_prep = QuantumCircuit(n_qubits + 1)
controlled_state_prep.cx(control, excitation)
controlled_state_prep.draw("mpl", fold=-1, scale=0.5)

מעגלי תבנית לחישוב איברי המטריצה של ו- דרך מבחן הדאמר
ההבדל היחיד בין המעגלים המשמשים במבחן הדאמר יהיה הפאזה באופרטור האבולוציה בזמן והאובייקטים הנמדדים. לכן אנחנו יכולים להכין מעגל תבנית המייצג את המעגל הגנרי למבחן הדאמר, עם מיקומי שמירה לשערים התלויים באופרטור האבולוציה בזמן.
# Parameters for the template circuits
parameters = []
for idx in range(1, krylov_dim):
parameters.append(dt_circ * (idx))
# Create modified hadamard test circuit
qr = QuantumRegister(n_qubits + 1)
qc = QuantumCircuit(qr)
qc.h(0)
qc.compose(controlled_state_prep, list(range(n_qubits + 1)), inplace=True)
qc.barrier()
qc.compose(qc_evol, list(range(1, n_qubits + 1)), inplace=True)
qc.barrier()
qc.x(0)
qc.compose(controlled_state_prep.inverse(), list(range(n_qubits + 1)), inplace=True)
qc.x(0)
qc.decompose().draw("mpl", fold=-1)
print(
"The optimized circuit has 2Q gates depth: ",
qc.decompose().decompose().depth(lambda x: x[0].num_qubits == 2),
)
The optimized circuit has 2Q gates depth: 50
עומק זה מופחת באופן משמעותי בהשוואה למבחן הדאמר המקורי. עומק זה ניתן לניהול במחשבים קוונטיים מודרניים, אם כי הוא עדיין גבוה למדי. נצטרך להשתמש בצמצום שגיאות מתקדם ביותר כדי לקבל תוצאות שימושיות.
בחר Backend שעליו להריץ את חישוב ה-Krylov הקוונטי שלנו, כדי שנוכל לבצע טרנספילציה של המעגל שלנו להרצה על אותו מחשב קוונטי.
# Use the least-busy backend or specify a quantum computer using the syntax commented out below.
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or you may choose a specify backend and channel if necessary for your workflow.
# service = QiskitRuntimeService(channel="ibm_quantum_platform")
# backend = service.backend("ibm_fez")
עכשיו אנחנו מבצעים טרנספילציה של המעגלים והאופרטורים שלנו.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
basis_gates = list(target.operation_names)
pm = generate_preset_pass_manager(
optimization_level=3, backend=backend, basis_gates=basis_gates
)
qc_trans = pm.run(qc)
print(qc_trans.depth(lambda x: x[0].num_qubits == 2))
print(qc_trans.count_ops())
qc_trans.draw("mpl", fold=-1, idle_wires=False, scale=0.5)
36
OrderedDict([('rz', 410), ('sx', 361), ('cz', 156), ('x', 18), ('barrier', 6)])

לאחר האופטימיזציה, עומק השני-Qubit של המעגל המטרנספל שלנו מופחת עוד יותר.
4.3 שלב 3. הרצה עם פרימיטיב Qiskit Runtime
עכשיו אנחנו יוצרים PUBs להרצה עם Estimator.
# Define observables to measure for S
observable_S_real = "I" * (n_qubits) + "X"
observable_S_imag = "I" * (n_qubits) + "Y"
observable_op_real = SparsePauliOp(
observable_S_real
) # define a sparse pauli operator for the observable
observable_op_imag = SparsePauliOp(observable_S_imag)
layout = qc_trans.layout # get layout of transpiled circuit
observable_op_real = observable_op_real.apply_layout(
layout
) # apply physical layout to the observable
observable_op_imag = observable_op_imag.apply_layout(layout)
observable_S_real = (
observable_op_real.paulis.to_labels()
) # get the label of the physical observable
observable_S_imag = observable_op_imag.paulis.to_labels()
observables_S = [[observable_S_real], [observable_S_imag]]
# Define observables to measure for H
# Hamiltonian terms to measure
observable_list = []
for pauli, coeff in zip(H_op.paulis, H_op.coeffs):
# print(pauli)
observable_H_real = pauli[::-1].to_label() + "X"
observable_H_imag = pauli[::-1].to_label() + "Y"
observable_list.append([observable_H_real])
observable_list.append([observable_H_imag])
layout = qc_trans.layout
observable_trans_list = []
for observable in observable_list:
observable_op = SparsePauliOp(observable)
observable_op = observable_op.apply_layout(layout)
observable_trans_list.append([observable_op.paulis.to_labels()])
observables_H = observable_trans_list
# Define a sweep over parameter values
params = np.vstack(parameters).T
# Estimate the expectation value for all combinations of
# observables and parameter values, where the pub result will have
# shape (# observables, # parameter values).
pub = (qc_trans, observables_S + observables_H, params)
מעגלים עבור ניתנים לחישוב קלאסי. אנחנו מבצעים זאת לפני שאנחנו עוברים למקרה באמצעות מחשב קוונטי.
from qiskit.quantum_info import StabilizerState, Pauli
qc_cliff = qc.assign_parameters({t: 0})
# Get expectation values from experiment
S_expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "X")
)
S_expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "Y")
)
# Get expectation values
S_expval = S_expval_real + 1j * S_expval_imag
H_expval = 0
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Get expectation values from experiment
expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "X")
)
expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "Y")
)
expval = expval_real + 1j * expval_imag
# Fill-in matrix elements
H_expval += coeff * expval
print(H_expval)
(10+0j)
למרות שהצלחנו להפחית את עומק השערים שלנו בסדרי גודל באמצעות מבחן הדאמר היעיל, העומק עדיין מספיק כדי לדרוש צמצום שגיאות מתקדם ביותר. בהמשך, אנחנו מציינים תכונות של הצמצום בשימוש. כל השיטות בשימוש חשובות, אך כדאי לציין במיוחד את הגברת שגיאות הסתברותית (PEA). טכניקה עוצמתית זו מגיעה עם עלות קוונטית רבה. החישוב שמתבצע כאן יכול לקחת 20 דקות או יותר להרצה על מחשב קוונטי אמיתי. ייתכן שתרצה לשחק עם הפרמטרים למטה כדי להגדיל או להפחית את הדיוק ובהתאם את העלות. ההגדרות ברירת המחדל למטה מניבות תוצאות באמינות גבוהה.
# Experiment options
num_randomizations = 300
num_randomizations_learning = 20
max_batch_circuits = 20
shots_per_randomization = 100
learning_pair_depths = [0, 4, 24]
noise_factors = [1, 1.3, 1.6]
# Base option formatting
options = {
# Builtin resilience settings for ZNE
"resilience": {
"measure_mitigation": True,
"zne_mitigation": True,
"zne": {"noise_factors": noise_factors},
# TREX noise learning configuration
"measure_noise_learning": {
"num_randomizations": num_randomizations_learning,
"shots_per_randomization": shots_per_randomization,
},
# PEA noise model configuration
"layer_noise_learning": {
"max_layers_to_learn": 10,
"layer_pair_depths": learning_pair_depths,
"shots_per_randomization": shots_per_randomization,
"num_randomizations": num_randomizations_learning,
},
},
# Randomization configuration
"twirling": {
"num_randomizations": num_randomizations,
"shots_per_randomization": shots_per_randomization,
"strategy": "all",
},
# Experimental settings for PEA method
"experimental": {
# # Just in case, disable any further qiskit transpilation not related to twirling / DD
# "skip_transpilation": True,
# Execution configuration
"execution": {
"max_pubs_per_batch_job": max_batch_circuits,
"fast_parametric_update": True,
},
# Error Mitigation configuration
"resilience": {
# ZNE Configuration
"zne": {
"amplifier": "pea",
"return_all_extrapolated": True,
"return_unextrapolated": True,
"extrapolated_noise_factors": [0] + noise_factors,
}
},
},
}
לבסוף, אנחנו מריצים את המעגלים עבור ו- עם Estimator.
# This job required 17 minutes of QPU time to run on a Heron r2 processor. This is only an estimate.
# Your execution time may vary.
with Batch(backend=backend) as batch:
# Estimator
estimator = Estimator(mode=batch, options=options)
job = estimator.run([pub], precision=1)
4.4 שלב 4. עיבוד לאחר הריצה וניתוח תוצאות
מה שקיבלנו מהמחשב הקוונטי הם אלמנטי המטריצה הבודדים של וקבוצות Pauli המתחלפות שמרכיבות את אלמנטי המטריצה של . יש לשלב את האיברים האלה כדי לשחזר את המטריצות שלנו, כך שנוכל לפתור את בעיית הערכים העצמיים המוכללת.
# Store the outputs as 'results'.
results = job.result()[0]
חישוב מטריצות ה-Hamiltonian האפקטיבי וה-Overlap
ראשית, נחשב את הפאזה שצברה המצב במהלך האבולוציה הזמנית הבלתי-מבוקרת
prefactors = [
np.exp(-1j * sum([c for p, c in H_op.to_list() if "Z" in p]) * i * dt)
for i in range(1, krylov_dim)
]
לאחר שיש לנו את תוצאות הרצת ה-Circuit, אפשר לעבד את הנתונים ולחשב את אלמנטי המטריצה של
# Assemble S, the overlap matrix of dimension D:
S_first_row = np.zeros(krylov_dim, dtype=complex)
S_first_row[0] = 1 + 0j
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[0][0][i] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[1][0][i] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
S_first_row[i + 1] += prefactors[i] * expval
S_first_row_list = S_first_row.tolist() # for saving purposes
S_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in it.product(range(krylov_dim), repeat=2):
if i >= j:
S_circ[j, i] = S_first_row[i - j]
else:
S_circ[j, i] = np.conj(S_first_row[j - i])
from sympy import Matrix
Matrix(S_circ)
ואת אלמנטי המטריצה של
import itertools
# Assemble S, the overlap matrix of dimension D:
H_first_row = np.zeros(krylov_dim, dtype=complex)
H_first_row[0] = H_expval
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[2 + 2 * obs_idx][0][
i
] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[2 + 2 * obs_idx + 1][0][
i
] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
H_first_row[i + 1] += prefactors[i] * coeff * expval
H_first_row_list = H_first_row.tolist()
H_eff_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in itertools.product(range(krylov_dim), repeat=2):
if i >= j:
H_eff_circ[j, i] = H_first_row[i - j]
else:
H_eff_circ[j, i] = np.conj(H_first_row[j - i])
from sympy import Matrix
Matrix(H_eff_circ)
לבסוף, אפשר לפתור את בעיית הערכים העצמיים המוכללת עבור :
ולקבל אומדן לאנרגיית מצב היסוד
gnd_en_circ_est_list = []
for d in range(1, krylov_dim + 1):
# Solve generalized eigenvalue problem
gnd_en_circ_est = solve_regularized_gen_eig(
H_eff_circ[:d, :d], S_circ[:d, :d], threshold=1e-1
)
gnd_en_circ_est_list.append(gnd_en_circ_est)
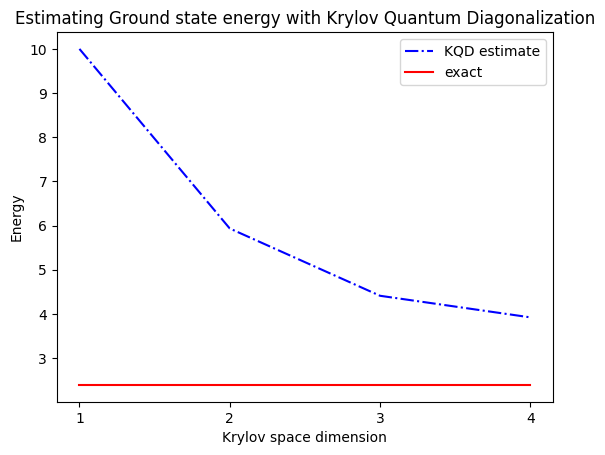
print("The estimated ground state energy is: ", gnd_en_circ_est)
The estimated ground state energy is: 10.0
The estimated ground state energy is: 5.933953916292923
The estimated ground state energy is: 4.4101773995740645
The estimated ground state energy is: 3.921288588521255
עבור סקטור חד-חלקיקי, אפשר לחשב ביעילות את מצב היסוד של סקטור זה של ה-Hamiltonian בצורה קלאסית
gs_en = single_particle_gs(H_op, n_qubits)
n_sys_qubits 10
n_exc 1 , subspace dimension 11
single particle ground state energy: 2.391547869638771
len(H_op)
27
plt.plot(
range(1, krylov_dim + 1),
gnd_en_circ_est_list,
color="blue",
linestyle="-.",
label="KQD estimate",
)
plt.plot(
range(1, krylov_dim + 1),
[gs_en] * krylov_dim,
color="red",
linestyle="-",
label="exact",
)
plt.xticks(range(1, krylov_dim + 1), range(1, krylov_dim + 1))
plt.legend()
plt.xlabel("Krylov space dimension")
plt.ylabel("Energy")
plt.title("Estimating Ground state energy with Krylov Quantum Diagonalization")
plt.show()
5. דיון והרחבה
לסיכום, אנחנו מתחילים ממצב ייחוס, ואז מאפשרים לו לאבולציה בפרקי זמן שונים כדי לייצר את תת-מרחב Krylov האוניטרי. אנחנו מקרינים את ה-Hamiltonian על אותו תת-מרחב. בנוסף אנחנו אומדים את ה-overlap בין וקטורי תת-המרחב. לבסוף, אנחנו פותרים קלאסית את בעיית הערכים העצמיים המוכללת על תת-המרחב בממדים נמוכים יותר.
בואו נשווה מה קובע את העלויות החישוביות של השימוש בטכניקת Krylov בצורה קלאסית וקוונטית. אין אנלוגיות מושלמות בין הגישות הקלאסיות והקוונטיות עבור כל השלבים. הטבלה הזו אוספת כמה סקלות של שלבים שונים לשיקול.
כדאי לזכור כי ל-Hamiltonians בדרך כלל יש איברים שלא ניתן למדוד בו-זמנית (כי הם לא מתחלפים זה עם זה). אנחנו ממיינים את האיברים ב-Hamiltonian לקבוצות של אופרטורי Pauli מתחלפים שניתן למדוד את כולם בו-זמנית, ויתכן שנצטרך קבוצות רבות כדי להכיל את כל האיברים שלא מתחלפים אחד עם השני. כדי לבנות את על מחשב קוונטי נדרשות מדידות נפרדות עבור כל קבוצה של מחרוזות Pauli מתחלפות ב-Hamiltonian, וכל אחת מהן דורשת shots רבים. עלינו לעשות זאת עבור אלמנטי מטריצה שונים, המתאימים ל- צירופים של גורמי אבולוציה זמנית שונים. לפעמים יש דרכים לצמצם זאת, אך בטיפול גס זה, הזמן הנדרש לכך מתסקל בערך האלמנטים של חייבים להיאמד, מה שמתסקל כ-. לבסוף, פתרון בעיית הערכים העצמיים המוכללת במרחב המוקרן, קלאסית, לוקח
אנחנו רואים שאלכסון Krylov קוונטי עשוי להיות שימושי במקרים שבהם מספר קבוצות Pauli המתחלפות ב-Hamiltonian קטן יחסית. תלויות הסקלה האלה מצביעות על יישומים מסוימים שבהם שיטת Krylov יכולה להיות שימושית, ואחרים שבהם ככל הנראה לא תהיה. ל-Hamiltonians מסוימים יש מורכבות גבוהה כשממפים לקיוביטים, הכוללת מחרוזות Pauli רבות שאינן מתחלפות ולא ניתן לחלקן בקלות לכמה קבוצות מתחלפות. זה לעתים קרובות נכון לבעיות כימיה קוונטית, לדוגמה. מורכבות זו מציגה שני אתגרים עיקריים למחשבים קוונטיים בטווח הקרוב:
- האמדה של כל אלמנט של הופכת יקרה חישובית בשל מספר האיברים הגדול.
- ה-Circuit של Trotter הנדרשים הופכים עמוקים מדי.
שתי הנקודות לעיל יהיו פחות בעייתיות כאשר המחשבים הקוונטיים יגיעו לסובלנות לתקלות, אך יש לקחת אותן בחשבון בטווח הקרוב. אפילו מערכות עם מיפויים "פשוטים" יותר מאלו בכימיה קוונטית עלולות להיתקל באותן מגבלות, אם ל-Hamiltonians שלהן יש יותר מדי איברים שאינם מתחלפים. שיטת Krylov שימושית ביותר כאשר ניתן לחלק את ה-Hamiltonian לכמה קבוצות מתחלפות יחסית של Pauli, וכאשר קל לממש ב-Circuit של Trotter. שתי התנאים האלה מתקיימים, לדוגמה, עבור מודלים רשת רבים שמעניינים בפיזיקה. KQD שימושי במיוחד כאשר ידוע מעט מאוד על מצב היסוד. הדבר נובע מערבויות ההתכנסות הטבועות בו ומיישמותו בתרחישים שבהם שיטות חלופיות אינן ישימות בשל ידע לא מספק על מצב היסוד.
למרות ש-KQD הוא כלי עוצמתי, ההיבטים הממושכים של הפרוטוקול — בעיקר האמדה של כל אלמנט של ה-Hamiltonian המוקרן ו-overlap של מצבי Krylov — מהווים הזדמנויות לשיפור. גישה חלופית כוללת שימוש בשיטות Krylov בשילוב עם שיטות מבוססות דגימה, שהן נושא השיעור הבא.
6. נספחים
נספח I: תת-מרחב Krylov מאבולוציות זמן אמיתי
מרחב Krylov האוניטרי מוגדר כ:
עבור צעד זמן שנקבע בהמשך. נניח זמנית ש- זוגי: אז נגדיר . נשים לב שכאשר אנחנו מקרינים את ה-Hamiltonian לתת-מרחב Krylov לעיל, הוא בלתי ניתן להבחנה מתת-מרחב Krylov
כלומר, כזה שבו כל האבולוציות הזמניות הוזזו אחורה ב- צעדי זמן. הסיבה שהם בלתי ניתנים להבחנה היא שאלמנטי המטריצה
אינווריאנטיים תחת הזזות כוללות של זמן האבולוציה, מכיוון שהאבולוציות הזמניות מתחלפות עם ה-Hamiltonian. עבור אי-זוגי, אפשר להשתמש בניתוח עבור .
אנחנו רוצים להראות שאי-שם בתת-מרחב Krylov הזה, מובטח שיהיה מצב בעל אנרגיה נמוכה. נעשה זאת באמצעות התוצאה הבאה, שנגזרת מ-Theorem 3.1 ב-[3]:
טענה 1: קיימת פונקציה כך שעבור אנרגיות בטווח הספקטרלי של ה-Hamiltonian (כלומר, בין אנרגיית מצב היסוד לאנרגיה המקסימלית)...
- עבור כל ערך שנמצא מ-, כלומר, הוא מדוכא אקספוננציאלית
- הוא קומבינציה לינארית של עבור
אנחנו נותנים הוכחה להלן, אך ניתן לדלג עליה בבטחה אלא אם רוצים להבין את הטיעון המלא והמחמיר. כעת נתמקד בהשלכות של הטענה לעיל. מתכונה 3 לעיל, אנחנו יכולים לראות שתת-מרחב Krylov המוזזה לעיל מכיל את המצב . זהו המצב בעל האנרגיה הנמוכה שלנו. כדי להבין מדוע, נכתוב את בבסיס עצמי אנרגטי:
כאשר הוא מצב עצמי האנרגיה ה-k ו- הוא האמפליטודה שלו במצב ההתחלתי . בביטוי זה, ניתן כ-
תוך שימוש בעובדה שאפשר להחליף ב- כאשר הוא פועל על מצב עצמי . שגיאת האנרגיה של מצב זה היא לפיכך
כדי להפוך זאת לחסם עליון קל יותר להבנה, נפריד תחילה את הסכום במונה לאיברים עם ואיברים עם :
אנחנו יכולים לחסום מעלה את האיבר הראשון על ידי ,
כאשר הצעד הראשון נובע מכך ש- עבור כל בסכום, והצעד השני נובע מכך שהסכום במונה הוא תת-קבוצה של הסכום במכנה. עבור האיבר השני, נחסום תחילה את המכנה מלמטה ב-, מכיוון ש-: חיבור הכל חזרה יחד נותן
כדי לפשט את מה שנשאר, נשים לב שעבור כל אלה, לפי הגדרת ידוע לנו ש-. בנוסף, חסימה עליונה של וחסימה עליונה של נותנות
זה מתקיים לכל , לכן אם נקבע שווה לשגיאת המטרה שלנו, חסם השגיאה לעיל מתכנס אליה אקספוננציאלית עם ממד Krylov . גם נשים לב שאם אז האיבר נעלם לחלוטין מהחסם לעיל.
להשלמת הטיעון, נשים לב תחילה שהאמור לעיל הוא רק שגיאת האנרגיה של המצב הספציפי , ולא שגיאת האנרגיה של המצב בעל האנרגיה הנמוכה ביותר בתת-מרחב Krylov. אולם, על פי עקרון הווריאציה (Rayleigh-Ritz), שגיאת האנרגיה של המצב בעל האנרגיה הנמוכה ביותר בתת-מרחב Krylov חסומה מעלה על ידי שגיאת האנרגיה של כל מצב בתת-המרחב, כך שהאמור לעיל הוא גם חסם עליון על שגיאת האנרגיה של המצב בעל האנרגיה הנמוכה ביותר, כלומר, הפלט של אלגוריתם אלכסון Krylov הקוונטי.
ניתוח דומה לזה לעיל ניתן לבצע תוך התחשבות בנוסף ברעש ובנוהל הסף שנדון במחברת. ראה [2] ו-[4] לניתוח זה.
נספח II: הוכחה של טענה 1
הדברים הבאים נגזרים בעיקר מ-[3], Theorem 3.1: יהיו ויהי מרחב הפולינומים השיוריים (פולינומים שערכם ב-0 הוא 1) בדרגה לכל היותר . הפתרון של
הוא
והערך המינימלי המתאים הוא
אנחנו רוצים להמיר זאת לפונקציה שניתן לבטא באופן טבעי במונחים של אקספוננציאלים מרוכבים, כי אלה הן האבולוציות הזמניות האמיתיות המייצרות את תת-מרחב Krylov הקוונטי. לשם כך, נוח להציג את ההמרה הבאה של אנרגיות בטווח הספקטרלי של ה-Hamiltonian למספרים בטווח : נגדיר
כאשר הוא צעד זמן כך ש-. נשים לב ש- ו- גדל כש- מתרחק מ-.
כעת, תוך שימוש בפולינום עם הפרמטרים a, b, d שנקבעים ל-, , ו-d = int(r/2), נגדיר את הפונקציה:
כאשר היא אנרגיית מצב היסוד. אנחנו יכולים לראות על ידי הצבת ש- הוא פולינום טריגונומטרי בדרגה , כלומר, קומבינציה לינארית של עבור . יתר על כן, מהגדרת לעיל מתקבל ש- ועבור כל בטווח הספקטרלי כך ש- מתקיים
מקורות:
[1] https://arxiv.org/abs/2407.14431
[2] https://arxiv.org/abs/1811.09025
[3] https://people.math.ethz.ch/~mhg/pub/biksm.pdf
[4] https://academic.oup.com/book/36426
[5] https://en.wikipedia.org/wiki/Krylov_subspace
[6] Krylov Subspace Methods: Principles and Analysis, Jörg Liesen, Zdenek Strakos https://academic.oup.com/book/36426
[7] Iterative Methods for Sparse Linear Systems" by Yousef Saad
[8] "MINRES-QLP: A Krylov Subspace Method for Indefinite or Singular Symmetric Systems" by Sou-Cheng Choi, Christopher Paige, and Michael Saunders (https://epubs.siam.org/doi/10.1137/100787921)
[9] Ethan N. Epperly, Lin Lin, and Yuji Nakatsukasa. "A theory of quantum subspace diagonalization". SIAM Journal on Matrix Analysis and Applications 43, 1263–1290 (2022).