פותר הערכים העצמיים הקוונטי הווריאציוני (VQE)
שיעור זה יציג את פותר הערכים העצמיים הקוונטי הווריאציוני, יסביר את חשיבותו כאלגוריתם יסודי בחישוב קוונטי, וגם יסקור את חוזקותיו וחולשותיו. VQE כשלעצמו, ללא שיטות משלימות, כנראה לא יספיק לחישובים קוונטיים בקנה מידה של שירות מודרני. עם זאת, הוא חשוב כשיטה היברידית-קלאסית-קוונטית מייצגת, וכבסיס חשוב עליו בנויים אלגוריתמים מתקדמים רבים יותר.
הסרטון הזה נותן סקירה של VQE ושל הגורמים המשפיעים על יעילותו. הטקסט שלהלן מוסיף פרטים נוספים ומממש VQE באמצעות Qiskit.
1. מהו VQE?
פותר הערכים העצמיים הקוונטי הווריאציוני הוא אלגוריתם המשתמש בחישוב קלאסי וקוונטי יחד כדי לבצע משימה. ל-VQE ארבעה רכיבים עיקריים:
- אופרטור: לעיתים קרובות Hamiltonian, שנקרא לו , המתאר תכונה של המערכת שלך שברצונך לייעל. דרך אחרת לומר זאת היא שאתה מחפש את הוקטור העצמי של האופרטור הזה המתאים לערך העצמי המינימלי. לעיתים קרובות נקרא לוקטור העצמי הזה "מצב היסוד".
- "ansatz" (מילה גרמנית שמשמעותה "גישה"): זהו Circuit קוונטי המכין מצב קוונטי המקרב את הוקטור העצמי שאתה מחפש. למעשה, ה-ansatz הוא משפחה של Circuits קוונטיים, כי חלק מה-Gates ב-ansatz הם פרמטריים, כלומר, הם מקבלים פרמטר שניתן לשנות. משפחת Circuits קוונטיים זו יכולה להכין משפחה של מצבים קוונטיים המקרבים את מצב היסוד.
- Estimator: אמצעי להערכת ערך הציפייה של האופרטור על המצב הקוונטי הווריאציוני הנוכחי. לפעמים מה שמעניין אותנו הוא פשוט ערך הציפייה הזה, שנקרא לו פונקציית עלות. לפעמים, אנחנו מתעניינים בפונקציה מסובכת יותר שעדיין ניתן לכתוב החל מערך ציפייה אחד או יותר.
- מייעל קלאסי: אלגוריתם המשנה פרמטרים בניסיון למזער את פונקציית העלות.
בואו נסתכל על כל אחד מהרכיבים הללו ביתר עומק.
1.1 האופרטור (Hamiltonian)
בלב בעיית VQE נמצא אופרטור המתאר מערכת מעניינת. נניח כאן שהערך העצמי הנמוך ביותר והוקטור העצמי המתאים לו שימושיים למטרה מדעית או עסקית כלשהי. דוגמאות עשויות לכלול Hamiltonian כימי המתאר מולקולה, כך שהערך העצמי הנמוך ביותר של האופרטור מתאים לאנרגיית מצב היסוד של המולקולה, והמצב העצמי המתאים מתאר את הגיאומטריה או תצורת האלקטרונים של המולקולה. או שהאופרטור יכול לתאר עלות של תהליך מסוים שיש לייעל, והמצבים העצמיים יכולים להתאים למסלולים או נוהלים. בתחומים מסוימים, כמו פיזיקה, "Hamiltonian" כמעט תמיד מתייחס לאופרטור המתאר את אנרגיית מערכת פיזית. אבל בחישוב קוונטי, נפוץ לראות אופרטורים קוונטיים המתארים בעיה עסקית או לוגיסטית שמכנים אותם גם "Hamiltonian". נאמץ מוסכמה זו כאן.

מיפוי בעיה פיזית או בעיית אופטימיזציה ל-Qubits הוא בדרך כלל משימה לא טריוויאלית, אך הפרטים הללו אינם מוקד הקורס הזה. דיון כללי על מיפוי בעיה לאופרטור קוונטי ניתן למצוא ב-חישוב קוונטי בפרקטיקה. מבט מפורט יותר על מיפוי בעיות כימיה לאופרטורים קוונטיים ניתן למצוא ב-כימיה קוונטית עם VQE.
לצורך קורס זה, נניח שצורת ה-Hamiltonian ידועה. לדוגמה, Hamiltonian עבור מולקולת מימן פשוטה (תחת הנחות מסוימות של מרחב פעיל, ובשימוש ב-Jordan-Wigner mapper) הוא:
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy
from qiskit.quantum_info import SparsePauliOp
hamiltonian = SparsePauliOp(
[
"IIII",
"IIIZ",
"IZII",
"IIZI",
"ZIII",
"IZIZ",
"IIZZ",
"ZIIZ",
"IZZI",
"ZZII",
"ZIZI",
"YYYY",
"XXYY",
"YYXX",
"XXXX",
],
coeffs=[
-0.09820182 + 0.0j,
-0.1740751 + 0.0j,
-0.1740751 + 0.0j,
0.2242933 + 0.0j,
0.2242933 + 0.0j,
0.16891402 + 0.0j,
0.1210099 + 0.0j,
0.16631441 + 0.0j,
0.16631441 + 0.0j,
0.1210099 + 0.0j,
0.17504456 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
],
)
שים לב שב-Hamiltonian לעיל, יש איברים כמו ZZII ו-YYYY שאינם מתחלפים זה עם זה. כלומר, כדי להעריך את ZZII, נצטרך למדוד את אופרטור פאולי Z על qubit 3 (בין מדידות אחרות). אבל כדי להעריך את YYYY, נצטרך למדוד את אופרטור פאולי Y על אותו qubit, qubit 3. קיים יחס אי-וודאות בין אופרטורי Y ו-Z על אותו qubit; איננו יכולים למדוד את שני האופרטורים הללו בו-זמנית. נחזור לנקודה זו להלן, ולאורך הקורס.
ה-Hamiltonian לעיל הוא אופרטור מטריצה . אלכסון האופרטור כדי למצוא את ערך האנרגיה העצמי הנמוך ביותר שלו אינו קשה.
import numpy as np
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues), "hartrees")
The ground state energy is -1.1459778447627311 hartrees
פותרי ערכים עצמיים קלאסיים בגסות לא יכולים לאפיין את האנרגיות או הגיאומטריות של מערכות אטומים גדולות מאוד, כמו תרופות או חלבונים. VQE הוא אחד הניסיונות הראשונים למנף חישוב קוונטי בבעיה זו.
נתקל ב-Hamiltonians גדולים בהרבה בשיעור זה מזה שלעיל. אבל יהיה זה בזבזני לדחוף את גבולות מה ש-VQE יכול לעשות, לפני שנציג כמה מהכלים המתקדמים יותר שיכולים להשלים או להחליף את VQE, בהמשך הקורס הזה.
1.2 Ansatz
המילה "ansatz" היא גרמנית ל"גישה". הרבים הנכון בגרמנית הוא "ansätze", אם כי לעיתים קרובות רואים "ansatzes" או "ansatze". בהקשר של VQE, ansatz הוא ה-Circuit הקוונטי שבו אתה משתמש כדי ליצור פונקציית גל של qubits מרובים שמקרבת בצורה הטובה ביותר את מצב היסוד של המערכת שאתה חוקר, ואשר מפיקה כך את ערך הציפייה הנמוך ביותר של האופרטור שלך. Circuit קוונטי זה יכיל פרמטרים ווריאציוניים (המאוגדים לעיתים קרובות יחד בוקטור המשתנים ).

נבחר ערכים התחלתיים של הפרמטרים הווריאציוניים. נקרא לפעולה האוניטרית של ה-ansatz על ה-Circuit . כברירת מחדל, כל ה-Qubits במחשבי הקוונטום של IBM® מאותחלים למצב . כאשר מריצים את ה-Circuit, מצב ה-Qubits יהיה
אם כל מה שהיינו צריכים הוא האנרגיה הנמוכה ביותר (בשפה של מערכות פיזיות), יכולנו להעריך זאת פשוט על ידי מדידת האנרגיה פעמים רבות ולקחת את הנמוכה ביותר. אבל בדרך כלל אנחנו גם רוצים את התצורה שמניבה את האנרגיה הנמוכה ביותר או הערך העצמי. אז השלב הבא הוא אומדן ערך הציפייה של ה-Hamiltonian, המושג באמצעות מדידות קוונטיות. יש הרבה מה שנכנס לכך. אבל אנחנו יכולים להבין את התהליך הזה איכותית על ידי ציון שהסתברות למדידת אנרגיה (שוב בשפה של מערכות פיזיות) קשורה לערך הציפייה לפי:
הסתברות קשורה גם לחפיפה בין המצב העצמי למצב הנוכחי של המערכת :
אז על ידי ביצוע מדידות רבות של אופרטורי פאולי המרכיבים את ה-Hamiltonian שלנו, אנחנו יכולים להעריך את ערך הציפייה של ה-Hamiltonian במצב הנוכחי של המערכת . השלב הבא הוא לשנות את הפרמטרים ולנסות להתקרב יותר למצב הנמוך-אנרגיה (היסוד) של המערכת. בגלל הפרמטרים הווריאציוניים ב-ansatz, לעיתים קרובות מכנים אותו הצורה הווריאציונית.
לפני שנעבור לתהליך הווריאציוני הזה, שים לב שלעיתים קרובות שימושי להתחיל את המצב שלך ממצב "ניחוש טוב". אולי אתה יודע מספיק על המערכת שלך כדי לעשות ניחוש התחלתי טוב יותר מ-. לדוגמה, נפוץ לאתחל qubits למצב Hartree-Fock ביישומים כימיים. ניחוש התחלתי זה שאינו מכיל פרמטרים ווריאציוניים נקרא מצב הייחוס. נקרא ל-Circuit הקוונטי המשמש ליצירת מצב הייחוס . בכל פעם שיש חשיבות להבחין בין מצב הייחוס לשאר ה-ansatz, השתמש ב: בשקילות
1.3 Estimator
אנחנו צריכים דרך להעריך את ערך הציפייה של ה-Hamiltonian שלנו במצב ווריאציוני מסוים . אם יכולנו למדוד ישירות את האופרטור כולו , זה היה פשוט כמו ביצוע מדידות רבות (נניח ) וממוצע הערכים הנמדדים:
כאן, סימן מזכיר לנו שערך הציפייה הזה יהיה מדויק רק בגבול כש-. אבל עם אלפי מדידות שמבוצעות על Circuit, שגיאת הדגימה של ערך הציפייה נמוכה למדי. קיימים שיקולים נוספים כמו רעש שהופכים לבעיה עבור חישובים מדויקים מאוד.
עם זאת, בדרך כלל לא ניתן למדוד את בבת אחת. עשוי להכיל אופרטורי פאולי X, Y ו-Z מרובים שאינם מתחלפים. לכן יש לפרק את ה-Hamiltonian לקבוצות של אופרטורים שניתן למדוד בו-זמנית, ויש להעריך כל קבוצה כזו בנפרד, ולשלב את התוצאות כדי לקבל ערך ציפייה. נחזור לכך ביתר פירוט בשיעור הבא, כאשר נדון בהתרחבות של גישות קלאסיות וקוונטיות. מורכבות המדידה הזו היא אחת הסיבות לכך שאנחנו צריכים קוד יעיל ביותר לביצוע הערכה כזו. בשיעור זה ובהמשך, נשתמש ב-Qiskit Runtime primitive Estimator למטרה זו.
1.4 מייעלים קלאסיים
מייעל קלאסי הוא כל אלגוריתם קלאסי שנועד למצוא קיצוניות של פונקציית יעד (בדרך כלל מינימום). הם מחפשים במרחב הפרמטרים האפשריים אחר קבוצה שממזערת פונקציית עניין כלשהי. ניתן לסווגם באופן כללי לשיטות מבוססות-גרדיאנט, המשתמשות במידע גרדיאנט, ולשיטות ללא-גרדיאנט, הפועלות כמייעלות קופסה שחורה. בחירת המייעל הקלאסי יכולה להשפיע משמעותית על ביצועי האלגוריתם, במיוחד בנוכחות רעש בחומרה קוונטית. מייעלים פופולריים בתחום זה כוללים Adam, AMSGrad ו-SPSA, שהראו תוצאות מבטיחות בסביבות רועשות. מייעלים מסורתיים יותר כוללים COBYLA ו-SLSQP.
תזרים עבודה נפוץ (מוצג בסעיף 3.3) הוא להשתמש באחד מהאלגוריתמים הללו כשיטה בתוך מייעל כמו פונקציית minimize של scipy. זו מקבלת כארגומנטים שלה:
- פונקציה כלשהי שיש למזער. זהו לעיתים קרובות ערך ציפייה האנרגיה. אבל אלה נקראים בדרך כלל "פונקציות עלות".
- קבוצת פרמטרים ממנה להתחיל את החיפוש. לעיתים קרובות נקרא או .
- ארגומנטים, כולל ארגומנטים של פונקציית העלות. בחישוב קוונטי עם Qiskit, ארגומנטים אלה יכללו את ה-ansatz, את ה-Hamiltonian ואת ה-Estimator primitive, שנדון בו יותר בתת-הסעיף הבא.
- 'שיטה' של מיזעור. זה מתייחס לאלגוריתם הספציפי המשמש לחיפוש במרחב הפרמטרים. כאן נציין לדוגמה COBYLA או SLSQP.
- אפשרויות. האפשרויות הזמינות עשויות להשתנות לפי שיטה. אבל דוגמה שכמעט כל השיטות יכללו היא מספר האיטרציות המקסימלי של המייעל לפני סיום החיפוש: 'maxiter'.

בכל שלב איטרטיבי, ערך הציפייה של ה-Hamiltonian מוערך על ידי ביצוע מדידות רבות. אנרגיה מוערכת זו מוחזרת על ידי פונקציית העלות, והמייעל מעדכן את המידע שיש לו על נוף האנרגיה. מה בדיוק עושה המייעל כדי לבחור את השלב הבא משתנה משיטה לשיטה. חלקם משתמשים בגרדיאנטים ובוחרים בכיוון הירידה התלולה ביותר. אחרים עשויים לקחת בחשבון רעש ועשויים לדרוש שהעלות תקטן בפער גדול לפני קבלת הנחה שהאנרגיה האמיתית פוחתת לאורך אותו כיוון.
# Example syntax for minimization
# from scipy.optimize import minimize
# res = minimize(cost_func, x0, args=(ansatz, hamiltonian, estimator), method="cobyla",
# options={'maxiter': 200})
1.5 העיקרון הווריאציוני
בהקשר זה, העיקרון הווריאציוני חשוב מאוד; הוא קובע שאף פונקציית גל ווריאציונית לא יכולה להניב ערך ציפייה של אנרגיה (או עלות) נמוך מזה שמניבה פונקציית גל מצב היסוד. מתמטית,
קל לאמת זאת אם נשים לב שקבוצת כל המצבים העצמיים של יוצרת בסיס שלם למרחב הילברט. במילים אחרות, כל מצב ובפרט ניתן לכתוב כסכום ממושקל (מנורמל) של המצבים העצמיים הללו של :
כאשר הם קבועים לקביעה, ו-. נשאיר זאת כתרגיל לקורא. אבל שים לב להשלכה: המצב הווריאציוני המניב את ערך ציפייה האנרגיה הנמוך ביותר הוא האומדן הטוב ביותר של מצב היסוד האמיתי.
בדוק את הבנתך
אמת מתמטית ש- עבור כל מצב ווריאציוני .
Answer
בשימוש בפיתוח הנתון של המצב הווריאציוני במונחי המצבים העצמיים של האנרגיה,
אנחנו יכולים לכתוב את ערך ציפייה האנרגיה הווריאציונית בתור
עבור כל המקדמים . אז נוכל לכתוב
2. השוואה עם תזרים עבודה קלאסי
נניח שאנחנו מתעניינים במטריצה עם N שורות ו-N עמודות. נניח שהמטריצה שלך כה גדולה שאלכסון מדויק אינו אפשרות. נניח עוד שאתה יודע מספיק על הבעיה שלך כדי לעשות כמה ניחושים על המבנה הכולל של המצב העצמי היעד, ואתה רוצה לבדוק מצבים דומים לניחוש ההתחלתי שלך כדי לראות אם ניתן להוריד עוד את העלות/אנרגיה שלך. זוהי גישה ווריאציונית, והיא שיטה אחת שנמצאת בשימוש כאשר אלכסון מדויק אינו אפשרות.
2.1 תזרים עבודה קלאסי
בשימוש במחשב קלאסי, זה יעבוד כך:
- עשה מצב ניחוש, עם כמה פרמטרים שתשנה: . למרות שניחוש התחלתי זה יכול להיות אקראי, זה לא מומלץ. אנחנו רוצים להשתמש בידע על הבעיה הנוכחית כדי להתאים את הניחוש שלנו ככל האפשר.
- חשב את ערך הציפייה של האופרטור כאשר המערכת במצב הזה:
- שנה את הפרמטרים הווריאציוניים וחזור: .
- השתמש במידע שנצבר על נוף המצבים האפשריים בתת-המרחב הווריאציוני שלך כדי לעשות ניחושים טובים יותר ויותר ולהתקרב למצב היעד. העיקרון הווריאציוני מבטיח שהמצב הווריאציוני שלנו לא יכול להניב ערך עצמי נמוך מזה של מצב היסוד היעד. אז ככל שערך הציפייה נמוך יותר, כך הקירוב שלנו למצב היסוד טוב יותר:
בואו נבחן את הקושי של כל שלב בגישה זו. הגדרה או עדכון פרמטרים היא מבחינה חישובית פשוטה; הקושי שם הוא בבחירת פרמטרים התחלתיים שימושיים ומוטיבציה פיזית. שימוש במידע שנצבר מאיטרציות קודמות לעדכון פרמטרים באופן שמתקרב למצב היסוד הוא לא טריוויאלי. אבל אלגוריתמי אופטימיזציה קלאסיים קיימים שעושים זאת בצורה יעילה למדי. אופטימיזציה קלאסית זו יקרה רק מכיוון שהיא עשויה לדרוש איטרציות רבות; במקרה הגרוע ביותר, מספר האיטרציות עשוי להתרחב באופן מעריכי עם N. השלב הבודד היקר ביותר מבחינה חישובית הוא כמעט בוודאות חישוב ערך הציפייה של המטריצה שלך בשימוש במצב נתון :
מטריצת חייבת לפעול על וקטור בגודל , מה שמתאים ל: פעולות כפל במקרה הגרוע ביותר. יש לבצע זאת בכל איטרציה של פרמטרים. עבור מטריצות גדולות מאוד, יש לכך עלות חישובית גבוהה.
2.2 תזרים עבודה קוונטי וקבוצות פאולי מתחלפות
עכשיו תאר לעצמך שאתה מעביר חלק זה של החישוב למחשב קוונטי. במקום לחשב ערך ציפייה זה, אתה מעריך אותו על ידי הכנת המצב על המחשב הקוונטי באמצעות ה-ansatz הווריאציוני שלך, ואז ביצוע מדידות.
זה אולי נשמע קל יותר ממה שהוא. בדרך כלל לא קל למדידה. לדוגמה, הוא יכול להיות מורכב מאופרטורי פאולי X, Y ו-Z רבים שאינם מתחלפים. אבל יכול להיכתב כצירוף לינארי של איברים, , שכל אחד מהם ניתן למדידה קלה (לדוגמה, אופרטורי פאולי או קבוצות של אופרטורי פאולי מתחלפים לפי qubit). ערך הציפייה של על מצב כלשהו הוא הסכום הממושקל של ערכי הציפייה של האיברים המרכיבים . ביטוי זה תקף לכל מצב , אבל נשתמש בו באופן ספציפי עם המצבים הווריאציוניים שלנו .
כאשר הוא מחרוזת פאולי כמו IZZX…XIYX, או מספר מחרוזות כאלה שמתחלפות זו עם זו. אז תיאור של ערך הציפייה שמתאים יותר למציאות המדידה על מחשבים קוונטיים הוא
ובהקשר של פונקציית הגל הווריאציונית שלנו:
כל אחד מהאיברים ניתן למדידה פעמים המניבות דגימות מדידה עם ומחזירות ערך ציפייה וסטיית תקן . אנחנו יכולים לסכם את האיברים הללו ולהפיץ שגיאות דרך הסכום כדי לקבל ערך ציפייה כולל וסטיית תקן .
זה לא דורש כפל בקנה מידה גדול, ולא כל תהליך שמתרחב בהכרח כמו . במקום זאת, זה דורש מדידות מרובות על המחשב הקוונטי. אם אין צורך ברבות מהן, גישה זו יכולה להיות יעילה. וזה החלק הקוונטי של VQE.
אבל בואו נדבר על סיבות מדוע זה עשוי להיות לא יעיל. סיבה אחת למדידות רבות היא להפחית את אי-הוודאות הסטטיסטית באומדנים שלך, עבור חישובים בדיוק גבוה מאוד. סיבה נוספת היא מספר מחרוזות פאולי הנדרשות לאפיין את המטריצה כולה. מכיוון שמטריצות פאולי (בתוספת הזהות: X, Y, Z ו-I) פורשות את המרחב של כל האופרטורים בממד נתון, מובטח לנו שנוכל לכתוב את המטריצה המעניינת שלנו כסכום ממושקל של אופרטורי פאולי, כפי שעשינו קודם.
כאשר הוא מחרוזת פאולי הפועלת על כל ה-Qubits המתארים את המערכת שלך כמו IZZX…XIYX, או מספר מחרוזות כאלה שמתחלפות זו עם זו. זכור שQiskit משתמשת בסימון little endian, בו אופרטור פאולי ה- מימין פועל על ה-Qubit ה-. אז אנחנו יכולים למדוד את האופרטור שלנו על ידי מדידת סדרה של אופרטורי פאולי.
אבל לא נוכל למדוד את כל אופרטורי פאולי הללו בו-זמנית. אופרטורי פאולי (למעט I) אינם מתחלפים זה עם זה אם הם קשורים לאותו qubit. לדוגמה, ניתן למדוד IZIZ ו-ZZXZ בו-זמנית, כי ניתן למדוד I ו-Z בו-זמנית עבור ה-Qubit השלישי, וניתן לדעת I ו-X בו-זמנית עבור ה-Qubit הראשון. אבל לא ניתן למדוד ZZZZ ו-ZZZX בו-זמנית, כי Z ו-X אינם מתחלפים, ושניהם פועלים על ה-Qubit ה-0. קוראים מנוסים אולי יזכרו שייתכן ששתי קבוצות של אופרטורי פאולי יתחלפו כקבוצה גם אם המדידות של כל qubit בנפרד אינן מתחלפות. Estimator מניח מדידות פאולי בתוצר טנסורי (באמצעות סיבובי בסיס), המתאים לקיבוץ אופרטורים שמתחלפים qubit-wise. לכן, כדי לאמוד בו-זמנית שתי מחרוזות (A ו-B) של אופרטורי פאולי באמצעות Estimator, אופרטורי פאולי של כל qubit ב-A ו-B חייבים להתחלף. המשמעות היא שגם לא ניתן למדוד ZZZZ ו-ZZXX בו-זמנית.

לכן אנחנו מפרקים את המטריצה שלנו לסכום של פאולי הפועלים על qubits שונים. חלק מהאיברים בסכום הזה ניתנים למדידה בבת אחת; אנחנו קוראים לזה קבוצה של פאולי מתחלפים. בהתאם לכמה איברים לא-מתחלפים יש, עשויות להיות דרושות קבוצות רבות כאלה. קרא למספר קבוצות כאלה של מחרוזות פאולי מתחלפות . אם קטן, זה יכול לעבוד טוב. אם ל- יש מיליוני קבוצות, זה לא יהיה שימושי.
התהליכים הנדרשים לאומדן ערך הציפייה מאוגדים יחד ב-Qiskit Runtime primitive שנקרא Estimator. למידע נוסף על Estimator, ראה את ה-API reference בתיעוד IBM Quantum®. ניתן פשוט להשתמש ב-Estimator ישירות, אבל Estimator מחזיר הרבה יותר מאשר רק ערך הערך העצמי הנמוך ביותר. לדוגמה, הוא גם מחזיר מידע על שגיאת תקן של הגדרה. לכן, בהקשר של בעיות מיזעור, לעיתים קרובות רואים את Estimator בתוך פונקציית עלות. למידע נוסף על קלטים ופלטים של Estimator ראה מדריך זה בתיעוד IBM Quantum.
אתה מתעד את ערך הציפייה (או פונקציית העלות) עבור קבוצת הפרמטרים שנמצאת בשימוש במצב שלך, ואז אתה מעדכן את הפרמטרים. לאורך זמן, יכולת להשתמש בערכי הציפייה או בערכי פונקציית העלות שהערכת כדי לקרב גרדיאנט של פונקציית העלות שלך בתת-מרחב המצבים שנדגמו על ידי ה-ansatz שלך. קיימים מייעלים קלאסיים הן מבוססי-גרדיאנט והן ללא-גרדיאנט. שניהם סובלים מבעיות אימון פוטנציאליות, כמו מינימה מקומיים מרובים, ואזורים גדולים של מרחב פרמטרים עם גרדיאנט קרוב לאפס, שנקראים רמות שוממות (barren plateaus).

2.3 גורמים הקובעים את העלות החישובית
VQE לא יפתור את כל בעיות הכימיה הקוונטית הקשות שלך. לא. אבל להיות טוב יותר בכל החישובים אינו הנקודה. שינינו את מה שקובע את העלות החישובית.

עברנו מתהליך שהמורכבות שלו תלויה רק בממד המטריצה לתהליך שתלוי בדיוק הנדרש ובמספר אופרטורי פאולי הלא-מתחלפים המרכיבים את המטריצה. הביט האחרון אין לו אנלוג בחישוב קלאסי.
בהתבסס על תלויות אלה, עבור מטריצות דלילות, או מטריצות הכוללות מעט מחרוזות פאולי לא-מתחלפות, תהליך זה עשוי להיות שימושי. זה המקרה עבור מערכות של ספינים מתקשרים, לדוגמה. עבור מטריצות צפופות, ייתכן שיהיה פחות שימושי. אנחנו יודעים לדוגמה שמערכות כימיות לעיתים קרובות כוללות Hamiltonians עם מאות, אלפים, אפילו מיליוני מחרוזות פאולי. נעשתה עבודה מעניינת להפחית את מספר האיברים הזה. אבל מערכות כימיות עשויות להיות מתאימות יותר לחלק מהאלגוריתמים האחרים שנדון בהם בקורס זה.
בדוק את הבנתך
שקול Hamiltonian על ארבעה qubits המכיל את האיברים:
IIXX, IIXZ, IIZZ, IZXZ, IXXZ, ZZXZ, XZXZ, ZIXZ, ZZZZ, XXXX
אתה רוצה למיין את האיברים הללו לקבוצות כך שניתן למדוד את כל האיברים בקבוצה בו-זמנית. מהו המספר המינימלי של קבוצות כאלה שניתן ליצור כך שכל האיברים מובאים בחשבון?
Answer
ניתן לעשות זאת ב-4 קבוצות. שים לב שפתרונות כאלה בדרך כלל אינם ייחודיים.
IIXX, XXXX, IIZZ, ZZZZ
IIXZ, IZXZ, ZIXZ, ZZXZ
IXXZ
XZXZ
מה לדעתך בדרך כלל מקשה על כימיה קוונטית עם VQE: מספר האיברים ב-Hamiltonian, או מציאת ansatz טוב?
Answer
מסתבר שיש ansätze שמותאמים מאוד להקשרים כימיים. מספר האיברים ב-Hamiltonian, ומכאן מספר המדידות הנדרשות, בדרך כלל גורמים לבעיות רבות יותר.
3. Hamiltonian לדוגמה
בוא נשים את האלגוריתם הזה לפועל באמצעות מטריצת המילטוניאן קטנה, כדי שנוכל לראות מה קורה בכל שלב. נשתמש במסגרת הדפוסים של Qiskit:
-שלב 1: מיפוי הבעיה למעגלים קוונטיים ואופרטורים -שלב 2: אופטימיזציה עבור חומרה יעד -שלב 3: ביצוע על חומרה יעד -שלב 4: עיבוד תוצאות לאחר הריצה
3.1 שלב 1: מיפוי הבעיה למעגלים קוונטיים ואופרטורים
נשתמש בזה שהגדרנו למעלה מהקשר הכימי. נתחיל עם כמה ייבואים כלליים.
# General imports
import numpy as np
# SciPy minimizer routine
from scipy.optimize import minimize
# Plotting functions
import matplotlib.pyplot as plt
שוב, אנחנו מניחים שההמילטוניאן הרצוי ידוע. נשתמש כאן בהמילטוניאן קטן מאוד, מכיוון ששיטות אחרות שנדון בהן בקורס זה יהיו יעילות יותר לפתרון בעיות גדולות יותר.
from qiskit.quantum_info import SparsePauliOp
import numpy as np
hamiltonian = SparsePauliOp.from_list(
[("YZ", 0.3980), ("ZI", -0.3980), ("ZZ", -0.0113), ("XX", 0.1810)]
)
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues))
The ground state energy is -0.702930394459531
יש הרבה אפשרויות ansatz מובנות מראש ב-Qiskit. נשתמש ב-efficient_su2.
# Pre-defined ansatz circuit and operator class for Hamiltonian
from qiskit.circuit.library import efficient_su2
# Note that it is more common to place initial 'h' gates outside the ansatz.
# Here we specifically wanted this layer structure.
ansatz = efficient_su2(
hamiltonian.num_qubits, su2_gates=["h", "rz", "y"], entanglement="circular", reps=1
)
num_params = ansatz.num_parameters
print("This circuit has ", num_params, "parameters")
ansatz.decompose().draw("mpl", style="iqp")
This circuit has 4 parameters
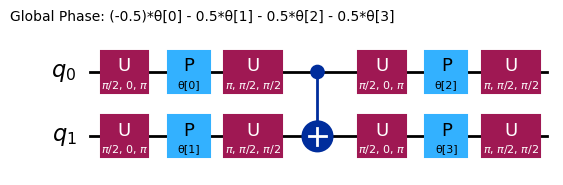
ל-ansätze שונות יהיו מבני שזירה שונים ו-Gate סיבוב שונים. זה שמוצג כאן משתמש ב-CNOT Gate לשזירה, וב-Y Gate ו-RZ Gate פרמטריים לסיבובים. שים לב לגודל מרחב הפרמטרים הזה; המשמעות היא שעלינו למזער את פונקציית העלות על פני 4 משתנים (הפרמטרים של ה-RZ Gate). ניתן להגדיל את זה, אבל לא ללא הגבלה. הרצת בעיה דומה על 4 qubit, באמצעות ברירת המחדל של 3 reps עבור efficient_su2, מניבה 16 פרמטרים וריאציוניים.
3.2 שלב 2: אופטימיזציה עבור חומרה יעד
ה-ansatz נכתב באמצעות Gate מוכרים, אך ה-Circuit שלנו חייב לעבור Transpile כדי להשתמש ב-Gate הבסיסיים שניתן לממש בכל מחשב קוונטי. אנחנו בוחרים את ה-Backend הפנוי ביותר.
# runtime imports
from qiskit_ibm_runtime import QiskitRuntimeService, Session
from qiskit_ibm_runtime import EstimatorV2 as Estimator
# To run on hardware, select the backend with the fewest number of jobs in the queue
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
print(backend)
<IBMBackend('ibm_torino')>
כעת אנחנו יכולים לבצע Transpile ל-Circuit שלנו עבור חומרה זו ולהמחיש את ה-ansatz לאחר ה-Transpile.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
ansatz_isa = pm.run(ansatz)
ansatz_isa.draw(output="mpl", idle_wires=False, style="iqp")

שים לב שה-Gate המשמשים השתנו, וה-Qubit במעגל המופשט שלנו מומפו ל-Qubit ממוספרים אחרת במחשב הקוונטי. עלינו למפות את ההמילטוניאן שלנו באופן זהה כדי שהתוצאות שלנו יהיו משמעותיות.
hamiltonian_isa = hamiltonian.apply_layout(layout=ansatz_isa.layout)
3.3 שלב 3: ביצוע על חומרה יעד
3.3.1 דיווח על ערכים
אנחנו מגדירים כאן פונקציית עלות שמקבלת כארגומנטים את המבנים שבנינו בשלבים הקודמים: הפרמטרים, ה-ansatz וההמילטוניאן. היא גם משתמשת ב-Estimator שעדיין לא הגדרנו. אנחנו כוללים קוד כדי לעקוב אחר ההיסטוריה של פונקציית העלות שלנו, כדי שנוכל לבדוק את התנהגות ההתכנסות.
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from Estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (EstimatorV2): Estimator primitive instance
cost_history_dict: Dictionary for storing intermediate results
Returns:
float: Energy estimate
"""
pub = (ansatz, [hamiltonian], [params])
result = estimator.run(pubs=[pub]).result()
energy = result[0].data.evs[0]
cost_history_dict["iters"] += 1
cost_history_dict["prev_vector"] = params
cost_history_dict["cost_history"].append(energy)
print(f"Iters. done: {cost_history_dict['iters']} [Current cost: {energy}]")
return energy
cost_history_dict = {
"prev_vector": None,
"iters": 0,
"cost_history": [],
}
זה מאוד יתרוני אם תוכל לבחור ערכי פרמטרים התחלתיים על בסיס ידע על הבעיה הנידונה ומאפייני המצב היעד. לא נעשה הנחות לגבי ידע כזה ונשתמש בערכים התחלתיים אקראיים.
x0 = 2 * np.pi * np.random.random(num_params)
# This required 13 min, 20 s QPU time on an Eagle processor, 28 min total time.
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
estimator.options.default_shots = 10000
res = minimize(
cost_func,
x0,
args=(ansatz_isa, hamiltonian_isa, estimator),
method="cobyla",
options={"maxiter": 50},
)
Iters. done: 1 [Current cost: 0.010575798722044727]
Iters. done: 2 [Current cost: 0.004040015974440895]
Iters. done: 3 [Current cost: 0.0020213258785942503]
Iters. done: 4 [Current cost: 0.18723082446726014]
Iters. done: 5 [Current cost: -0.2746792152068885]
Iters. done: 6 [Current cost: -0.3094547651648519]
Iters. done: 7 [Current cost: -0.05281985428356641]
Iters. done: 8 [Current cost: 0.00808560303514377]
Iters. done: 9 [Current cost: -0.0014821685303514388]
Iters. done: 10 [Current cost: -0.004759824281150161]
Iters. done: 11 [Current cost: 0.09942328705995292]
Iters. done: 12 [Current cost: 0.01092366214057508]
Iters. done: 13 [Current cost: 0.05017497496069776]
Iters. done: 14 [Current cost: 0.13028868414310696]
Iters. done: 15 [Current cost: 0.013747803514376994]
Iters. done: 16 [Current cost: 0.2583072432944498]
Iters. done: 17 [Current cost: -0.14422125655131562]
Iters. done: 18 [Current cost: -0.0004950150347678081]
Iters. done: 19 [Current cost: 0.00681082268370607]
Iters. done: 20 [Current cost: -0.0023377795527156544]
Iters. done: 21 [Current cost: 0.6027665591169237]
Iters. done: 22 [Current cost: 0.00596641373801917]
Iters. done: 23 [Current cost: -0.008318769968051117]
Iters. done: 24 [Current cost: -0.00026683306709265246]
Iters. done: 25 [Current cost: -0.007648222843450479]
Iters. done: 26 [Current cost: 0.004121086261980831]
Iters. done: 27 [Current cost: -0.004075019968051117]
Iters. done: 28 [Current cost: -0.004419369009584665]
Iters. done: 29 [Current cost: 0.213185460054037]
Iters. done: 30 [Current cost: -0.06505919572162797]
Iters. done: 31 [Current cost: -0.5334241316590271]
Iters. done: 32 [Current cost: 0.00218370607028754]
Iters. done: 33 [Current cost: 0.09579352143666908]
Iters. done: 34 [Current cost: -0.009274800319488819]
Iters. done: 35 [Current cost: -0.44395141360688106]
Iters. done: 36 [Current cost: 0.011747104632587858]
Iters. done: 37 [Current cost: -0.003344149361022364]
Iters. done: 38 [Current cost: 0.19138183916486304]
Iters. done: 39 [Current cost: 0.013513931813145209]
אפשר לבחון את הפלטים הגולמיים.
res
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.5334241316590271
x: [ 1.024e+00 6.459e+00 3.625e+00 4.007e+00]
nfev: 39
maxcv: 0.0
3.4 שלב 4: עיבוד תוצאות לאחר הריצה
אם הפרוצדורה מסתיימת כהלכה, אז הערכים במילון שלנו צריכים להיות שווים לוקטור הפתרון ולמספר הכולל של הערכות הפונקציה, בהתאמה. קל לוודא זאת:
cost_history_dict
{'prev_vector': array([1.02397956, 6.45886604, 3.62479262, 4.00744128]),
'iters': 39,
'cost_history': [np.float64(0.010575798722044727),
np.float64(0.004040015974440895),
np.float64(0.0020213258785942503),
np.float64(0.18723082446726014),
np.float64(-0.2746792152068885),
np.float64(-0.3094547651648519),
np.float64(-0.05281985428356641),
np.float64(0.00808560303514377),
np.float64(-0.0014821685303514388),
np.float64(-0.004759824281150161),
np.float64(0.09942328705995292),
np.float64(0.01092366214057508),
np.float64(0.05017497496069776),
np.float64(0.13028868414310696),
np.float64(0.013747803514376994),
np.float64(0.2583072432944498),
np.float64(-0.14422125655131562),
np.float64(-0.0004950150347678081),
np.float64(0.00681082268370607),
np.float64(-0.0023377795527156544),
np.float64(0.6027665591169237),
np.float64(0.00596641373801917),
np.float64(-0.008318769968051117),
np.float64(-0.00026683306709265246),
np.float64(-0.007648222843450479),
np.float64(0.004121086261980831),
np.float64(-0.004075019968051117),
np.float64(-0.004419369009584665),
np.float64(0.213185460054037),
np.float64(-0.06505919572162797),
np.float64(-0.5334241316590271),
np.float64(0.00218370607028754),
np.float64(0.09579352143666908),
np.float64(-0.009274800319488819),
np.float64(-0.44395141360688106),
np.float64(0.011747104632587858),
np.float64(-0.003344149361022364),
np.float64(0.19138183916486304),
np.float64(0.013513931813145209)]}
fig, ax = plt.subplots()
x = np.linspace(0, 10, 50)
# Define the constant function
constant = -0.7029
y_constant = np.full_like(x, constant)
ax.plot(
range(cost_history_dict["iters"]), cost_history_dict["cost_history"], label="VQE"
)
ax.set_xlabel("Iterations")
ax.set_ylabel("Cost")
ax.plot(y_constant, label="Target")
plt.legend()
plt.draw()

ל-IBM Quantum יש הצעות הכשרה נוספות הקשורות ל-VQE. אם אתה מוכן ליישם VQE בפועל, ראה במדריך שלנו: אמידת אנרגיית המצב הבסיסי של שרשרת Heisenberg עם VQE. אם אתה רוצה מידע נוסף על יצירת המילטוניאנים מולקולריים, ראה בשיעור זה בקורס שלנו על כימיה קוונטית עם VQE. אם אתה מעוניין בהבנה עמוקה יותר של כיצד אלגוריתמים וריאציוניים כמו VQE עובדים, אנחנו ממליצים על הקורס עיצוב אלגוריתמים וריאציוניים.
בדוק את הבנתך
בסעיף זה, חישבנו אנרגיית מצב בסיסי מהמילטוניאן. אם היינו רוצים ליישם זאת כדי, נניח, לקבוע את הגיאומטריה של מולקולה, כיצד היינו מרחיבים זאת?
Answer
היינו צריכים להכניס משתנים למרווח בין-אטומי ולזוויות בין הקשרים. היינו צריכים לשנות אותם. עבור כל שינוי של אלה, היינו מייצרים המילטוניאן חדש (מכיוון שהאופרטורים המתארים את האנרגיה בהחלט תלויים בגיאומטריה). עבור כל המילטוניאן כזה שמיוצר וממופה על qubit, היינו צריכים לבצע אופטימיזציה כמו זו שנעשתה למעלה. מכל הבעיות המרובות האלה של אופטימיזציה שהתכנסו, הגיאומטריה שייצרה את האנרגיה הנמוכה ביותר היא זו שהטבע יאמץ. זה מורכב הרבה יותר ממה שהוצג למעלה. חישוב כזה נעשה עבור המולקולה הפשוטה ביותר, , כאן.
4. הקשר של VQE לשיטות אחרות
בסעיף זה נסקור את היתרונות והחסרונות של גישת VQE המקורית ונצביע על הקשריה לאלגוריתמים אחרים וחדשים יותר.
4.1 החוזקות והחולשות של VQE
חלק מהחוזקות כבר צוינו. הן כוללות:
- התאמה לחומרה מודרנית: חלק מהאלגוריתמים הקוואנטיים דורשים שיעורי שגיאה נמוכים הרבה יותר, שמתקרבים לסובלנות תקלות בקנה מידה גדול. VQE לא דורש זאת; ניתן לממש אותו במחשבים קוואנטיים עכשוויים.
- Circuit-ים רדודים: VQE משתמש לרוב ב-Circuit-ים קוואנטיים רדודים יחסית. זה הופך את VQE לפחות רגיש לשגיאות Gate מצטברות ומאפשר שימוש בטכניקות רבות להפחתת שגיאות. כמובן, ה-Circuit-ים לא תמיד רדודים; זה תלוי ב-ansatz שנבחר.
- גמישות: VQE יכול (עקרונית) להיושם על כל בעיה שניתן לנסח אותה כבעיית ערך עצמי/וקטור עצמי. יש הסתייגויות רבות שהופכות את VQE לבלתי מעשי או לא אידיאלי עבור בעיות מסוימות. חלקן מסוכמות להלן.
חלק מהחולשות של VQE ובעיות שעבורן הוא לא מעשי תוארו גם לעיל. הן כוללות:
- אופי היוריסטי: VQE לא מבטיח התכנסות לאנרגיית מצב היסוד הנכונה, שכן ביצועיו תלויים בבחירת ה-ansatz ושיטות האופטימיזציה[1-2]. אם נבחר ansatz גרוע שחסר את השזירה הנדרשת למצב היסוד הרצוי, אף אופטימייזר קלאסי לא יוכל להגיע למצב היסוד הזה.
- פרמטרים רבים פוטנציאליים: ansatz מאוד אקספרסיבי עשוי לכלול כל כך הרבה פרמטרים שאיטרציות המינימיזציה גוזלות זמן רב מאוד.
- עלות מדידה גבוהה: ב-VQE, Estimator משמש להערכת ערך הציפייה של כל איבר בהמילטוניאן. לרוב ההמילטוניאנים המעניינים יהיו איברים שלא ניתן להעריך בו-זמנית. זה עלול להפוך את VQE לדורש משאבים רבים עבור מערכות גדולות עם המילטוניאנים מורכבים[1].
- השפעות רעש: כאשר האופטימייזר הקלאסי מחפש מינימום, חישובים רועשים עלולים לבלבל אותו ולהרחיקו מהמינימום האמיתי או לעכב את התכנסותו. פתרון אפשרי אחד הוא מינוף טכניקות מתקדמות להפחתת שגיאות וסופרסיה של שגיאות[2-3] מ-IBM.
- מישורים שוממים (Barren plateaus): אזורים אלה של גרדיאנטים דועכים[2-3] קיימים גם בהיעדר רעש, אך הרעש מחמיר אותם מכיוון שהשינוי בערכי הציפייה עקב רעש עשוי להיות גדול יותר מהשינוי הנובע מעדכון פרמטרים באזורים שוממים אלה.
4.2 קשר לגישות אחרות
Adapt-VQE
אלגוריתם ADAPT-VQE (Adaptive Derivative-Assembled Pseudo-Trotter Variational Quantum Eigensolver) הוא שיפור של אלגוריתם VQE המקורי, שתוכנן לשפר יעילות, דיוק ויכולת קנה מידה עבור סימולציות קוואנטיות, במיוחד בכימיה קוואנטית.
אלגוריתם VQE המקורי שתואר לאורך השיעור הזה משתמש ב-ansatz קבוע ומוגדר מראש כדי לקרב את מצב היסוד של המערכת. במקרה שלנו, השתמשנו ב-efficient_su2, עם חזרה אחת, תוך שימוש ב-Gate-ים של סיבוב Y ו-RZ. למרות שהפרמטרים ב-Gate-ים של RZ השתנו, מבנה ה-ansatz הזה וה-Gate-ים שנעשה בהם שימוש לא השתנו.
ADAPT-VQE מתמודד עם המגבלות של VQE דרך בניית ansatz אדפטיבי. במקום להתחיל עם ansatz קבוע, ADAPT-VQE בונה את ה-ansatz באופן דינמי ואיטרטיבי. בכל שלב, הוא בוחר את האופרטור מתוך מאגר מוגדר מראש (כגון אופרטורי עירור פרמיוניים) שיש לו את הגרדיאנט הגדול ביותר ביחס לאנרגיה. זה מבטיח שרק האופרטורים בעלי ההשפעה הגדולה ביותר יתווספו, מה שמוביל ל-ansatz קומפקטי ויעיל[4-6]. לגישה זו יכולות להיות מספר השפעות מועילות:
- הפחתת עומק ה-Circuit: על ידי גידול ה-ansatz באופן הדרגתי והתמקדות רק באופרטורים הנחוצים, ADAPT-VQE ממזער פעולות Gate בהשוואה לגישות VQE מסורתיות[5,7].
- שיפור דיוק: האופי האדפטיבי מאפשר ל-ADAPT-VQE לשחזר יותר אנרגיית קורלציה בכל שלב, מה שהופך אותו ליעיל במיוחד עבור מערכות עם קורלציה חזקה שבהן VQE מסורתי מתקשה[8,9].
- יכולת קנה מידה ועמידות לרעש: ה-ansatz הקומפקטי מפחית הצטברות של שגיאות Gate, מפחית עלות חישובית ומגביל את מספר הפרמטרים הוריאציוניים שיש למזערם.
ADAPT-VQE עדיין לא מושלם. במקרים מסוימים הוא עלול להיתקע או להאט בגלל מינימומים מקומיים, וייתכן שיסבול מפרמטריזציה יתרה. הוא גם עלול לדרוש משאבים רבים, מכיוון שהוא מחייב חישוב גרדיאנטים ואופטימיזציית פרמטרים עם מבני Gate רבים.
הערכת פאזה קוואנטית (QPE)
QPE דומה במטרתו ל-VQE, אך שונה מאוד ביישום. QPE דורש מחשבים קוואנטיים עמידים לתקלות בשל ה-Circuit-ים הקוואנטיים העמוקים בדרך כלל ורמת הקוהרנטיות הגבוהה שהוא דורש. כאשר ניתן יהיה לממש QPE, הוא יהיה מדויק יותר מ-VQE. דרך אחת לתאר את ההבדל היא דרך הדיוק כפונקציה של עומק ה-Circuit. QPE משיג דיוק עם עומקי Circuit שמתרחבים כ- [10]. VQE דורש דגימות להשגת אותו דיוק[10,11].
Krylov, SQD, QSCI, ואחרים בקורס הזה
VQE עזר לבסס אלגוריתמים קוואנטיים שעדיין תלויים במחשבים קלאסיים, לא רק להפעלת המחשב הקוואנטי, אלא עבור חלקים מהותיים של האלגוריתם. מספר אלגוריתמים כאלה הם המוקד של יתרת הקורס הזה. כאן אנחנו נותנים הסבר שטחי לכמה מהם, פשוט כדי להשוות ולהניגד אותם ל-VQE. הם יוסברו בפירוט רב יותר בשיעורים הבאים.
דיאגונליזציה קוואנטית של Krylov (KQD)
שיטות מרחב Krylov הן דרכים להטיל מטריצה על תת-מרחב כדי לצמצם את מימדה ולהפוך אותה לניהולית יותר, תוך שמירה על המאפיינים החשובים ביותר. טריק אחד בשיטה זו הוא ליצור תת-מרחב ששומר על מאפיינים אלה; מסתבר שיצירת תת-מרחב זה קשורה קשר הדוק לשיטה מבוססת ומוכרת במחשבים קוואנטיים הנקראת Trotterization.
ישנן מספר וריאנטים של שיטות Krylov קוואנטיות, אך בדרך כלל הגישה היא:
- שימוש במחשב הקוואנטי ליצירת תת-מרחב (מרחב Krylov) דרך Trotterization
- הטלת המטריצה המעניינת על מרחב Krylov זה
- דיאגונליזציה של ההמילטוניאן המוטל החדש בעזרת מחשב קלאסי
דיאגונליזציה קוואנטית מבוססת דגימה (SQD)
דיאגונליזציה קוואנטית מבוססת דגימה (SQD) קשורה לשיטת Krylov בכך שגם היא מנסה לצמצם את מימד המטריצה לדיאגונליזציה תוך שמירה על מאפיינים מרכזיים. SQD עושה זאת בדרך הבאה:
- התחלה עם ניחוש ראשוני למצב היסוד והכנת המערכת במצב יסוד זה.
- שימוש ב-Sampler לדגימת ה-bitstring-ים המרכיבים מצב זה.
- שימוש באוסף מצבי הבסיס החישובי מה-Sampler כתת-המרחב שעליו מטילים את המטריצה המעניינת.
- דיאגונליזציה של המטריצה הקטנה יותר, המוטלת, בעזרת מחשב קלאסי.
זה קשור ל-VQE בכך שהוא ממנף מחשוב קלאסי וקוואנטי עבור רכיבי אלגוריתם מהותיים. לשניהם יש גם דרישה משותפת שנכין ניחוש ראשוני טוב או ansatz. אך חלוקת העבודה בין המחשבים הקלאסי והקוואנטי ב-SQD דומה יותר לזו של שיטת Krylov.
למעשה, שיטת Krylov ו-SQD שולבו לאחרונה לשיטת דיאגונליזציה קוואנטית של Krylov מבוססת דגימה (SKQD) [12].
אינטראקציה קונפיגורציה תת-מרחב קוואנטי
QSCI (Quantum Selected Configuration Interaction)[13] הוא אלגוריתם שמייצר מצב יסוד מקורב של המילטוניאן על ידי דגימת פונקציית גל ניסיונית לזיהוי מצבי הבסיס החישובי המשמעותיים ליצירת תת-מרחב לדיאגונליזציה קלאסית. גם SQD וגם QSCI משתמשים במחשב קוואנטי לבניית תת-מרחב מצומצם. החוזקה הנוספת של QSCI היא בהכנת המצב שלו, במיוחד בהקשר של בעיות כימיה. הוא ממנף אסטרטגיות שונות כגון שימוש במצבים שעברו אבולוציה בזמן [14] וסט של ansätze בהשראת כימיה. על ידי התמקדות בהכנת מצב יעילה, QSCI מפחית עלויות חישוב קוואנטי עבור המילטוניאנים כימיים תוך שמירה על נאמנות גבוהה ומינוף עמידות לרעש מטכניקות דגימת מצב קוואנטי [15]. QSCI גם מספק טכניקת בנייה אדפטיבית שמספקת ansätze נוספים לתוצאה טובה יותר.
תהליך העבודה הברירת מחדל של QSCI לבעיות כימיה הוא כדלקמן:
- בניית ההמילטוניאן המולקולרי באמצעות תוכנה לבחירתך (כגון SciPy).
- הכנת אלגוריתם QSCI על ידי בחירת מצב ראשוני מתאים ו-ansatz בהשראת כימיה עם סט פרמטרים שנבחר מראש.
- דגימת מצבי בסיס משמעותיים ודיאגונליזציה של ההמילטוניאן בעזרת מחשב קלאסי לקבלת אנרגיית מצב היסוד.
- לעיתים קרובות משתמשים בשחזור קונפיגורציה [16] ובסלקציה לאחר עיבוד לפי סימטריה [15] כטכניקת עיבוד לאחר מדידה.
- אופציונלית, תהליך העבודה של ADAPT-QSCI כולל לולאת אופטימיזציה נוספת משלב 2 לשלב 3, באמצעות ansätze נוספים עם מצבים ראשוניים אקראיים.
בדוק את הבנתך
מה משותף ל-VQE ולכל שאר השיטות המפורטות לעיל (מלבד QPE שלא תואר בפירוט רב)
Answer
כל השיטות כוללות מצב ניסיוני או פונקציית גל מסוג כלשהו. כולן עובדות בצורה הטובה ביותר כאשר הניחוש הראשוני למצב ניסיוני זה מצוין.
תשובה נכונה נוספת היא שכולן קלות יותר ליישום כאשר ההמילטוניאן קל למדידה (ניתן למיין אותו לקבוצות מועטות יחסית של אופרטורי Pauli מתחלפים).
מה יש ל-VQE שאין לאף אחת מהשיטות האחרות המפורטות לעיל?
Answer
אופטימייזרים קלאסיים. אף אחת מהשיטות האחרות לא משתמשת באלגוריתמי אופטימיזציה קלאסיים לבחירת פרמטרים וריאציוניים.
מקורות
[2] https://en.wikipedia.org/wiki/Variational_quantum_eigensolver
[3] https://journals.aps.org/prapplied/abstract/10.1103/PhysRevApplied.19.024047
[4] https://arxiv.org/abs/2111.05176
[6] https://inquanto.quantinuum.com/tutorials/InQ_tut_fe4n2_2.html
[7] https://www.nature.com/articles/s41467-019-10988-2
[8] https://arxiv.org/abs/2210.15438
[9] https://journals.aps.org/prresearch/abstract/10.1103/PhysRevResearch.6.013254
[10] https://arxiv.org/html/2403.09624v1
[11] https://www.nature.com/articles/s42005-023-01312-y
[13] https://arxiv.org/abs/1802.00171
[14] https://arxiv.org/abs/2103.08505
[15] https://arxiv.org/html/2501.09702v1
[16] https://quri-sdk.qunasys.com/docs/examples/quri-algo-vm/qsci/
[17] https://arxiv.org/abs/2412.13839